
Stelo Technical Documents
Using the SQDR v5 Kafka Producer
Last Update: 29 December 2022
Product: StarQuest Data Replicator
Version: SQDR 5.18 or later
Article ID: SQV00DR034
Abstract
This tech note describes how to install and configure the SQDR Kafka Producer (a Db2 LUW stored procedure) and a Stelo-supplied sample Kafka consumer.
Deprecation notice: This information is provided for historical purposes. If you are using SQDR v6 or later, we recommend using SQDR Streaming Support or other v6 functionality such as Stelo Data Lake Sink Connectors instead.
Apache Kafka is an open-source message broker project that aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. The design is heavily influenced by transaction logs.
The Kafka interface can also be used to communicate with cloud-based streaming services such as Azure Event Hubs for Kafka, the Oracle Cloud Infrastructure Streaming service, Amazon Managed Streaming for Apache Kafka, and IBM Event Streams.
Customers requiring high speed access to legacy system change data (such as IBM Db2, Oracle and Microsoft SQL Server) to drive information into new generation data engines, such as Apache Hive, MongoDB, Hadoop, MemSQL, Cassandra, Azure Storage, Azure Data Lake Storage, etc. will find their requirements well met by the StarQuest real time replication solution, SQDR.
Setup Procedure:
Setting up the StarQuest Kafka files
Setting up Kafka and System environment variables
Local hosts File
Install the SQDR Kafka Producer as a Java stored procedure in the local SQDRC control database
Creating the Incremental Group
Configuring and Starting the Kafka Consumer
Troubleshooting
Reference:
JSON or XML Format
Replay
Azure Event Hubs and Azure Data Lake Store
Oracle Cloud Streaming Service
Amazon Managed Streaming for Apache Kafka
Hints and FAQ
Overview
SQDR provides support for streaming change data to Apache Kafka consumers. The Stelo-provided Kafka Producer may be associated with an incremental group containing one or more subscriptions. The producer injects a message for each subscribed table’s activity, with one message for each Insert, Update and Delete DML operation. While each group may be associated with only one producer; multiple groups may be configured to use different producers which may also share common source tables. No customization of the producer code is required to use the functionality.
In addition to the SQDR Producer, a sample consumer is provided as Java source code. The sample illustrates parsing the message and exploiting the message details. Users are encouraged to utilize this sample as a template for creating custom consumers.
The architecture relies upon the SQDR Change Data Processing support. The Kafka producer runs as a cached stored procedure within the SQDR-supplied Db2 for LUW control database. Each change row processed by the incremental support is passed to the stored procedure and injected as a message. Reliable, high speed distribution of the message is a service of the Kafka message bus.
Prerequisites
Download the binary distribution of Kafka from https://kafka.apache.org/downloads.html; at the time of the latest revision of this document, the current version is kafka_2.13-2.8.1.tgz (Kafka 2.8.1 built with Scala 2.13). On Windows, you will need 7-zip or another compression utility to unpack the .tgz file, or contact StarQuest support for a .zip distribution. The use of Kafka 3.0.x is not supported, as support for JRE8 has been deprecated in that version.
Download Kafka.zip, containing the StarQuest Producer and source and binary files for the sample Consumer, along with installation scripts.
You must be using SQDR 5.18 or later and Db2 11.x for the SQDR control database. The producer runs as a Java stored procedure within the local Db2 LUW control database.
If you are using a combined tier solution, the installer for SQDR Plus contains a public JRE that is used by the installation scripts and by the sample Consumer.
If you are using a split tier scenario, use Db2 LUW 11.x (instead of SQL Server) for the control database. You will also need a JRE to install the stored procedure and to run the sqdrJdbcBaseline and ProcTester apps; you can use the JRE supplied with Db2 ("C:\Program Files\IBM\SQLLIB\java\jdk\bin\java").
To customize the Consumer, you will need a Java IDE (e.g. Eclipse) and the JDK.
You also need to know the IP address or hostname and port that your Kafka server is listening on.
Upgrade Information
Beginning with SQDR 5.18, Kafka connection & topic information is supplied using the Parameters button on the Incremental Group Advanced Dialog. The original method of using the group Comment field is deprecated, though it is still functional for now. If information is present in both the Comment field and the Parameters dialog, the latter is used - i.e. the Comment field should now be used only for Description.
If you are running a pre-.5.18 version of the stored procedure, you must update the TOKAFKA stored procedure using the replace.bat or replace.sh script in the JARS subdirectory. Restart Db2 after updating the stored procedure.
If you are using the sqdrJdbcBaseline application, edit your .cfg files and change any use of semicolon in the kafkaproperties to the pipe (|) character.. Previous versions of this utility expected that multiple lines would be separated with a semicolon; this has been changed to the pipe character in order to support complex multi-line connection strings such as those used by Azure Event Hubs for Kafka.
SETUP PROCEDURE:
Setting up the StarQuest Kafka files
The StarQuest-supplied files are supplied as a zip file; extract this zip file into C:\dev\kafka. In addition to the ready-to-run jar files in C:\dev\Kafka\KafkaProcedure\jars, the source directories can be imported into Eclipse.
Setting up Kafka and System environment variables
- Download the binary distribution for Kafka and extract it to a directory of your choice; we recommend using a directory path without spaces. In our setup, the Kafka installation directory is C:\bin\kafka..
- Create a new system environment variable KAFKALIB containing the path to the lib subdirectory of your Kafka installation:
e.g. create an environment KAFKALIB set to the value C:\bin\kafka\libs
- Modify the CLASSPATH system environment variable, adding
%KAFKALIB%/;
Note: the wildcard entry %KAFKALIB%\* is sufficient use by the sample consumer and by the SQDRJdbcBaseline application, but using %KAFKALIB%/ is needed by the SQDR Producer, which runs as a Java stored procedure in Db2 LUW.
- Reboot the system so that the new CLASSPATH value is available to Java stored procedures running under Db2.
Editing Local hosts File (uncommon)
When the Kafka producer communicates with the Kafka server, the server may return its hostname. If your DNS system is not configured to resolve that hostname correctly, open C:\Windows\System32\drivers\etc\hosts in Notepad or another text editor and add line similar to the following:
172.19.36.175 mykafka.mydomain.com
Install the SQDR Kafka Producer as a Java stored procedure in the local SQDRC control database
- Open a command window.
- cd C:\dev\Kafka\KafkaProcedure\jars
- Open install.bat in Notepad or another editor and update directory locations and password if necessary. The credentials are those of the local Windows user sqdr that SQDR uses to access the local Db2 database.
- Run install.bat - this calls SQLJ.INSTALL_JAR() to create the Java stored procedure and calls CREATE PROCEDURE to register it.
To update the Java stored procedure at a later time, edit and run replace.bat.
The SQL script createproc.sql is supplied for informational and troubleshooting purposes.
Creating the Incremental Group
If it does not already exist, use Data Replicator Manager to create an incremental group and add subscriptions.
Here are some configuration hints:
If the goal is to send the change data as a Kafka message, rather than updating a destination, create the group and subscriptions as follows:
You may use the control database (SQDRC) as the "destination", even if it doesn’t match the “true” destination type – e.g. MemSQL.
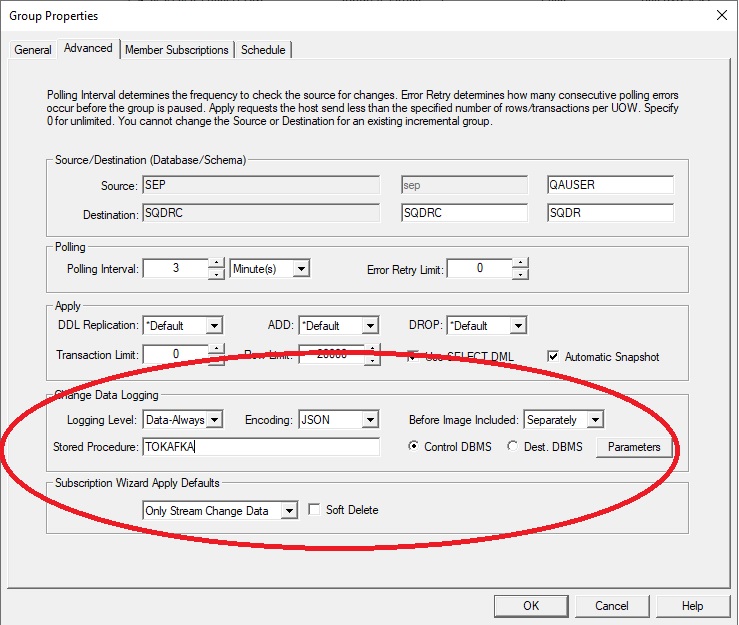
Create the I/R group first, specifying the following on the Advanced panel::
- Change Apply/Row Limit from 2000 to 20000.
- Change Data Logging:
Logging Level: Data-Always
Select the Control DBMS radio button
Stored Procedure: TOKAFKA
(This will invoke the stored procedure locally in the SQDRC context.) - Select the Parameters button and enter the connection information in the dialog.
In some cases, this may be a single line e.g.
bootstrap.servers=172.19.36.175:9092
or it might be several lines long, such as a connection to Azure Event Hubs for Kafka.
Optional: The default value for the Kafka topic is the group name, with spaces replaced by underscore. You can override the default by entering the following line in the Parameters dialog:
topic=My_Topic
- If desired, select the Encoding (JSON, XML, or *Default). If you select *Default, the default encoding (JSON unless otherwise specified on the useXMLEncoding Advanced Setting) is used. If you configured local.encoding (XML or JSON) in the Comment field of the group in versions of SQDR prior to 5.10 (e.g. when configuring the Kafka Producer), that value will be used to set the Encoding parameter when you update to 5.10, after which local.encoding in the Comment field will be ignored.
If desired, select a value for Before Image (*Default, Combined, Separately). If you select *Default, the value defined in the Change Data Logging Defaults section of the Replication tab of the SQDR Service properties is used. See the Advanced Tab for Groups of Incremental Subscriptions topic of the SQDR Help file for more details about this parameter.
- Subscription Wizard Apply Defaults:
Select Only Stream Change Data – this indicates that Apply will not attempt to perform any operations on the destination tables.
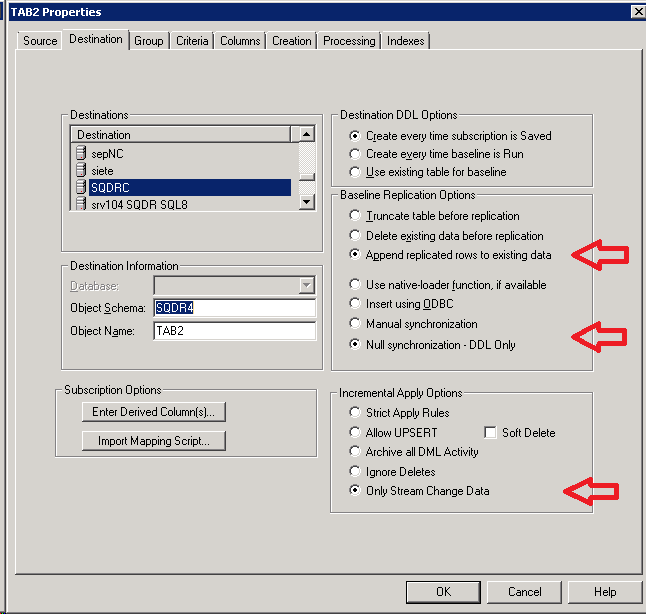
Create subscriptions by selecting Members under the group and choosing Insert Member (rather than creating subscriptions under the Source). When creating the subscriptions, specify the following on the Destination panel:
- For I/R Apply Options, confirm that Only Stream Change Data is selected. This setting is inherited from the group default, and insures that no attempt is made to apply change data into the destination; only the stored procedure will be invoked. Note that this setting may be greyed-out after setting the following options.
- For Baseline Replication Options, specify Append replicated rows to existing data
and Null synchronization - DDL Only, so that no baseline activity will occur. These settings insure that “running the baseline” does not result in an error; however, the subscription is successfully “registered” with the Capture Agent.
Run the Subscription:
After creating the Subscriptions, enable capture & apply.by running the subscriptions.
Configuring and Starting the Kafka Consumer
- Edit consumer.bat or consumer.sh and set the TOPIC variable. This value is used as the Kafka topic.
e.g.
set TOPIC=Sample_Group - Delete any old copies of kafka.properties and run consumer.bat or consumer.sh once to create kafka.properties.
- Edit kafka.properties and modify this line, supplying the IP address or hostname and port of your Kafka server, including the backslash character:
bootstrap.servers=172.19.36.175\:9092 - Optional: Add a line like the following. This value does not have to match the name of the IR group, as long as it is unique (e.g. if you are running multiple groups, and thus multiple producer/consumer pairs, using a unique ID)
group.id=MY_IR_GROUP - Run consumer.bat or consumer.sh again. This time, the application will continue to run and start to display data received from the SQDR Producer. The sample consumer parses the XML or JSON data structure supplied by the Producer and sends the output to stdout. You can redirect the output to a file if desired e.g. C> consumer > output.txt.
- Enter control-C to terminate the application.
Troubleshooting
Limited troubleshooting capabilities are available when invoking the Producer stored procedure from SQDR. See below for ProcTester Java application, which calls the Java stored procedure in the same manner as SQDR.
However, more common problems such as basic connectivity can be tested using other techniques.
Some common errors/troubleshooting techniques:
- Make sure that you are using the correct name for the Kafka library - Kafka uses libs rather than the more typical lib for the directory name.
- Check for typos; it is not uncommon to accidentally enter TOKAKFA or SDQR.
- Verify connectivity to the Kafka server, checking both hostname and port. You can use something like
telnet <host> <port>
or the PowerShell command
Test-NetConnection -ComputerName <host> -Port <port> - If you plan to use TLS encrypted communication to the Kafka server (typically port 9094) rather than plain text (typically port 9092), you may need to work with certificate management and your connection string will be more complicated.
- The sqdrJdbcBaseline application can be used for testing connectivity/functionality, since it does not use the Db2 stored procedure at all.
- If the I/R group is in error (icon is either red toggling between red and green), check the Application Event for errors e.g.
Procedure or user-defined function SQDR.TOKAFKA aborted with an exception Failed to construct kafka producer
and check db2diag.log for a similar error, which may have additional information e.g. the following will occur when an invalid hostname or IP address is supplied in Parameters.
No resolvable bootstrap urls given in bootstrap.servers
- Another error that might appear in db2diag.log is when Db2 is unable to allocate enough memory to start the stored procedure. Add memory and/or restart Db2 if necessary; increasing the Db2 instance parameter JAVA_HEAP_SZ (using db2 update dbm cfg) may help.
ProcTester
To assist with troubleshooting, the ProcTester Java application is provided. To run ProcTester, obtain the HEXID of the incremental group and modify and run ProcTester.bat.
Note: The current version of ProcTester only works when SQDR is configured to send JSON. An older version of ProcTester that works with XML is located in the subdirectory ProcTester.XML.
Note: The current version of ProcTester works only if the Kafka connection information is stored in original location of the group Comment field rather than the Parameters button on the Incremental Group Advanced Dialog. It is OK to place the connection information in both places, but they should match.
Obtain the Group ID
After the I/R group is created, you can obtain its ID, which is a 32 character GUID stored in the SQDRC control database. This value is used by the test utility.
You can obtain its value by executing the following SQL from a Db2 command window (db2cmd):
db2> connect to SQDRC user SQDR using <password>
db2> select id from SQDR.GROUPS where GROUP_NAME like 'MY_IR_GROUP'
ID
-----------------------------------
x'03A6116FDE36CE49B0978E50B4487365'
You can also use IBM Data Studio to examine the SQDR.GROUPS table.
Configure and run ProcTester
- Edit ProcTester.bat and set HEXID to the Group ID value obtained in the previous step.
- Update directory locations and password if necessary. The credentials are those of the local Windows user sqdr that SQDR uses to access the local Db2 database.
- Run ProcTester.bat from a command window.
If you get the error Missing required configuration "bootstrap.servers" which has no default value, confirm that you have configured the correct HEXID and that the bootstrap.servers value has been configured in the Comment of the group.
sqdrJdbcBaseline Application
The SQDR Kafka Producer described above produces only change data. The sqdrJdbcBaseline application supplements that support by providing a method of performing a baseline of the desired table, resulting in Kafka output that can be read by the same consumer. Output of the baseline application can be formatted as JSON or XML, and is identical to that produced by the SQDR Kafka Producer except for producing an operation code of "L" (Load) rather than "I" (Insert).
The sqdrJdbcBaseline directory contains the following files:
- sqdrJdbcBaseline.jar
- sqdrJdbcBaseline.bat
- drivers\ - a subdirectory containing JDBC drivers for all supported host databases
- sample_configs\ - a subdirectory containing sample configurations for all supported host databases
Setup
- If necessary, edit the batch file and define the location of the Kafka distribution.
- Choose a config file from the sample_configs directory and copy it to the main directory, renaming it as desired. We suggest using an identifying name such as the host system's hostname.
- Edit the configuration file e.g. mysys.cfg:
- The group is obtained from the SQDR Plus control tables (SQDRPn) with the following SQL. This parameter is optional; unless your consumer requires it, in most cases you can ignore this parameter, though a value should still be provided.
select SUBSCRIBERID from sqdr.sq_subscribers where SUBSCRIBERNAME like '%<subscriber>%'
- Customize the other fields e.g sourceurl, sourceuser, sourcepassword, sql, topic. If you have defined an SQDR Plus agent for the source system, you can refer to the agent configuration (sqagent.properties) for the sourceurl.
- There is no need to configure the TABLE name if your specify SQL that creates the desired output.
- Interval value of 5000 = 5 seconds.
- kafkaproperties contains connection info e.g. the hostname or IP address and port of the Kafka server. In the case of Azure Event Hubs for Kafka, the connection info consists of several lines, which can be copied from the Azure Portal. Multiple lines should be separated with a pipe (|) character.
If the value of kafkaproperties is the string "KAFKAPROPERTIES", then the kafka.properties file is used instead. - Optionally, use the Topic property to overrride the default of using the I/R group name as topic.
- Optionally, you can define a Topic name or the choice of JSON or XML output by appending these parameters to kafkaproperties (separated by the pipe character) .e.g
"kafkaproperties": "bootstrap.servers=172.19.36.175:9092|Topic=My_Topic|local.encoding=JSON"
- Invoke the batch file, supplying the config file name (without the .cfg extension).
C> sqdrJdbcBaseline mysys
You can supply multiple config files e.g.
C> sqdrJdbcBaseline sys1 sys2 sys3
If you invoke the batch file without supplying a config name, the batch file will use a config file with the same basename as the batch file; for example, invoking sqdrJdbcBaseline is the same as invoking sqdrJdbcBaseline sqdrJdbcBaseline (where there is a config file named .sqdrJdbcBaseline.cfg).
JSON or XML Format
JSON encoding (default) generally results in shorter strings, and is more readily parsed by Java applications.
You may configure SQDR to produce XML output rather than the default of JSON by setting the encoding in the group, or setting the advanced setting useXMLEncoding=1 (the latter is global, affecting all I/R groups). Your consumer application needs to be able to parse the XML output.
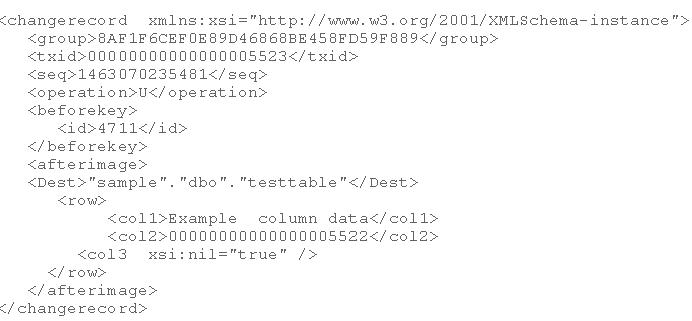
Below is an example of the XML format produced by the TOKAFKA stored procedure for an Update operation. The Consumer needs to be able to parse and interpret this information.
Here is an example of the JSON format for a simple Insert operation:
{"group":"4DEC433B09A62C4DA6646BF4EE1A3F30",
"txid":"00000000000000000109",
"seq":1566511556144,
"operation":"I",
"beforekey":null,
"dest":"\"SQDR\".\"TAB1\"",
"row":{"FLD1": "10173", "FLD2": "new line", "FLD4": "100"}}
The group is always present and contains the GUID of the Group to which the Subscription belongs.
The txid is the SQDR Plus-generated hex-binary transaction id for the change record. Note that this is not the transaction id from the source system.
The seq is a BIGINT sequence number that represents the relative order in which the update occurs in the source log within a given transaction. For a given source log, it is also the sequential order in which the operation was processed within the log. It can be used in conjunction with txid and Dest to detect Change Data Replay, if that functionality is needed by the Consumer. See Replay below for more information.
The operation (type) is always present. Its value is one of I/D/U for Insert/Delete/Update source-table operations. There are additional operations that the Consumer may need to process.
- S indicates that the subscription needs to be rebaselined. This can be an indication of a REORG at the source or that there is a disruption of the SQDR Plus Capture Agent’s log reading position.
- X indicates that the source table has been dropped. An A operation indicates that the source table has been altered.
- B operation may be generated for subscriptions with “criteria” (i.e. a where clause). This additional change data row sent for each update contains the values of all the columns prior to the update. This option is not available for some source databases, such Db2 for i for with *AFTER journaling or SQL Server sources.
- C indicates that all change records collected during a baseline copy have been processed. This record can refer to baselines for other groups or even other agents subscribing to the same table.
The beforekey is available for U and D records. If the subscription is configured to use RRN, it contains values for the RRN column. Otherwise if will contain the column values of the source table’s primary key, or the aggregate columns of unique indexes when no primary key exists.
The afterimage always contains the Dest element which identifies the table the operation pertains to. The afterimage optionally contains a row element that contain column values for an Insert or Update.
NULL values in columns or before keys are indicated by the xsi:nil attribute. Binary (char for bit data) columns are encoded in hexBinary.
The XmlRowParser.java and JsonRowParser.java files contain sample parsers that illustrates how to interpret the XML and JSON records sent by the SQDR Kafka Producer. The parsers are used by the supplied sample/test Kafka Consumer.
Replay
Pausing SQDR client operations, disruption in availability of the SQDR Plus Capture Agent or killing/stopping the SQDR service can result in replaying change records to the Kafka Consumer.
In order to detect replay, the Consumer needs to track txid and seq for each subscribed table. If txid is less than the txid of the last processed record for the table, the record can be ignored as a replay. If the txid matches the txid of the last processed record, the records can be ignored if the seq is less than or equal to the seq of the last processed record.
Azure Event Hubs and Azure Data Lake Store
Azure Event Hubs for Kafka can be used in place of a Kafka cluster, either as a message broker between the SQDR Producer and a consumer (as described above), or as a method of storing data into Azure Blob Storage or Azure Data Lake Store.
You must be using the Standard or Premium pricing tier; Kafka support is not available at the Basic tier.
The connection information for Azure Event Hubs consists of several complex lines and is more complicated than a typical Kafka connection string. See the Microsoft documentation Get an Event Hubs connection string for information on obtaining the connection string from Settings/Shared access policies. Select the primary Connection String and use that information to create a connection information that looks something like this (you will need to update the bootstrap.servers and password fields - i.e. the fields in italics below):
bootstrap.servers=myeventhub.servicebus.windows.net:9093
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="Endpoint=sb://myeventhub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=ArOQYqH0SqmRYbeO6McNHuTKXXXdYawK050LQhXpWI0=";
Supply this information to the Kafka Producer by pasting it as-is into the Properties dialog on the Advanced panel of the I/R Group.
To supply this information to the sqdrJdbcBaseline application, do one of the following:
- Place the multi-line contents into a file called kafka.properties and set "kafkaproperties":"KAFKAPROPERTIES"
- Replace newlines with the pipe (|) character.
When configuring Azure Event Hubs, you may need to add the IP address of your SQDR server to the firewall exception list.in Settings/Networking. However, this appears to be unnecessary for this particular usage.
In addition to creating the Event Hub name space, you can create an Event Hub using a name that matches a Kafka Topic. If an Event Hub by that name does not exist, it will be automatically created when a Producer or a Consumer connects.
Select Features/Capture of the Event Hub if you wish to store the data in an Azure Storage Account (also used by Azure Data Lake Store Gen 2) or Azure Data Lake Store Gen 1.
Troubleshooting: In the Azure Portal, examine the list of Event Hubs in your Event Hub Namespace. A typo in the name of a Topic (or I/R group) defined in SQDR will result in the creation of a Event Hub with the mistyped name.
References:
- Use Azure Event Hubs from Apache Kafka applications
- Quickstart: Data streaming with Event Hubs using the Kafka protocol
- Get an Event Hubs connection string
Oracle Cloud Streaming Service
The Oracle Cloud Streaming Service can be used in place of a Kafka cluster, as a message broker between the SQDR Producer and a consumer.
First, use the Oracle Cloud console to verify that your Oracle Cloud account is enabled for streaming:
Under Governance and Administration/Governance/Limits, Quotas and Usage:
Select the Service Streaming from the dropdown and verify the values for:
Connect Harness Count - at least 1
Partition Count - number of streams (aka topics) that you plan to use
Configuration of Streaming can be found under Solutions & Platforms/Analytics/Streaming.
You may Ignore Kafka Connection Configuration - this is used for communications between an Oracle database and Kafka, and is not relevant to this application.
You do not need to create a stream (which is equivalent to a topic), as that will be created automatically when the producer or client connects with a topic name.
If the DefaultPool doesn't already exist, create a pool under Stream Pools. Select Settings of the Stream Pool and verify that the checkbox AUTO CREATE TOPICS is enabled. Alternatively, you can create the stream (with a name that matches the topic) in advance.
View Kafka Connection Settings and select Copy All Settings to obtain the connection string. However, this connection string will need to be modified with the appropriate user and AUTH_TOKEN.
Next, create a user, group, and policy:
- Go to Governance and Administration/Identity/Users
- Create a dedicated user for the streaming service: streaming-user
- On the user details page, generate an auth token. Copy this token, as you will not be able to retrieve it later.
- Under Governance and Administration/Identity/Groups: create a group StreamingUsers and add the streaming-user to the group
- Under Governance and Administration/Identity/Policies, create Policy StreamingUsersPolicy and add the following:
allow group StreamingUsers to manage streams in tenancy
allow group StreamingUsers to manage stream-pull in tenancy
allow group StreamingUsers to manage stream-push in tenancy
You can now use this user and its AUTH-TOKEN with the connection string that was obtained from the Pool. The username consists of 3 components - tenancy/userID/ocid. If the phrase oracleidentitycloudservice appears as a fourth component, remove it.
Copy the connection string into kafka.properties in the Consumer directory and start the consumer. Verify that the consumer starts without error; you should see the topic appear as a stream in the Oracle console.
To test connectivity from Oracle Streaming Service to the consumer, select the stream in the console and select Produce Test Message. If you enter a malformed string, it may result in an error at the Producer, but that is sufficient to show connectivity. If you are using the supplied Consumer sample, paste in the following string:
{"group":"d761072ab77ee34cb6fb4117bd1fa142","txid":null,"seq":1,"operation":"L","beforekey":null,"dest":"\"MYSCHEMA\".\"MYTABLE\"","row":{"ID":"0","DESCRIP":"Other"}}
For more information about configuring the Oracle Cloud Streaming Service, see the blog posting Migrate Your Kafka Workloads To Oracle Cloud Streaming.
Amazon Managed Streaming for Apache Kafka (MSK)
Amazon Managed Streaming for Apache Kafka (MSK) can be used in place of a Kafka cluster, either as a message broker between the SQDR Producer and a consumer (as described above), or as a method of storing data into a destination such as Amazon Redshift or Amazon S3 object store (using AWS Glue or using Kafka-Kinesis-Connector and Amazon Kinesis Data Firehose), or supplying data to an analysis tool such as Amazon Kinesis Data Analytics.
For more information see Using SQDR and Amazon Managed Streaming for Kafka.
Hints and FAQ
Question: How can we identify in the output that is published to Kafka which attributes are used as a primary key or in unique indexes? We would use this metadata on the target system to build relationships between documents.
Answer: Within the Change Record, the "Before key" element provides the columns and value pairs associated with the primary key (or unique columns) which may be used to identify the row being reported (for "U" and "D" opcodes).
Symptom: The following error occurred when running INSTALL.BAT to create the stored procedure in the control database:
SQL20201N The install, replace or remove of jar-id failed as the jar name is invalid.
Solution: This error indicates that the stored procedure has already been installed (or at least KAFKAPROCS_JAR.jar already exists in C:\ProgramData\IBM\DB2\DB2COPY1\function\jar\SQDR)
You can use REPLACE.BAT to update the contents of the jar, though this will not affect the registration of the stored procedure.
To remove the stored procedure (so you can run INSTALL.BAT again) run the following in the Db2 command line environment:
C> db2 connect to SQDRC user sqdr
password: <password>
db2> drop procedure SQDR.TOKAFKA
db2> call sqlj.remove_jar( KAFKAPROCS_JAR )
Symptom: The following messages appear in db2diag.log and the Application event log when SQDR calls the TOKAFKA stored procedure:
ADM10000W A Java exception has been caught. The Java stack traceback has been written to the db2diag log file.
java.lang.NoClassDefFoundError: org.apache.kafka.clients.producer.KafkaProducer
at com.starquest.udb.kafka.KafkaProcedure.TOKAFKA(KafkaProcedure.java:108)
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.clients.producer.KafkaProducer
at java.net.URLClassLoader.findClass(URLClassLoader.java:607)
Solution: This error could be a result of inability to load one or more of the Kafka libraries that were added to the CLASSPATH environment variable. Examine the CLASSPATH for any typos and verify that all of the specified files exist in the specified location.
Symptom: The following error occurred in the Kafka server (running on Windows) when adding a topic::
java.io.IOException: The requested operation cannot be performed on a file with a user-mapped section open at java.io.RandomAccessFile.setLength(Native Method)
Solution: Topic names are case-sensitive, but (on Windows) file and directory names are not. When the Kafka server is running on a system with case-sensitive filenames, specifying topic names in different cases will result in the creation of separate topics. However, on Windows, specifying a topic name that differs only in case from an existing topic (e.g. TEST and test) will result in the above error.
DISCLAIMER
The information in technical documents comes without any warranty or applicability for a specific purpose. The author(s) or distributor(s) will not accept responsibility for any damage incurred directly or indirectly through use of the information contained in these documents. The instructions may need to be modified to be appropriate for the hardware and software that has been installed and configured within a particular organization. The information in technical documents should be considered only as an example and may include information from various sources, including IBM, Microsoft, and other organizations.