
Stelo Technical Documents
Using SQDR Streaming Support with Confluent
Last Update: 10 Aug 2023
Product: StarQuest Data Replicator
Version: SQDR 6.20 or later
Article ID: SQV00DR052
Abstract
SQDR Streaming Support provides a mechanism to apply incremental change data from legacy DBMS systems (such as IBM Db2, Oracle, Microsoft SQL Server, MySQL and Informix) into new generation data engines using Apache Kafka, an open-source message broker project that provides a unified, high-throughput, low-latency platform for handling real-time data feeds.
See SQDR Streaming Support for an overview and instructions for configuring SQDR to deliver baseline and incremental changes to a customer-written Kafka Consumer through Apache Kafka, Azure Event Hubs, or other Kafka-compatible services.
SQDR now supports replicating to Confluent, an Apache Kafka managed service. Confluent offers the following products:
- Confluent Platform: An enterprise-grade distribution of Apache Kafka for on-prem and private cloud environments
- Confluent Cloud: A fully managed, cloud-native service
- Confluent Connectors: An extensive portfolio of pre-built Kafka connectors for relational and non-relational databases and other targets.
This technical document describes the steps needed to configure Confluent to receive and apply baselines and incremental changes from SQDR into targets supported by Confluent Connectors.
- Overview
- Prerequisites
- Creating the Destination
- Creating the Incremental (I/R) Group
- Creating the Incremental (I/R) Subscription(s)
- Troubleshooting
- Hints and FAQ
Overview
SQDR provides support for streaming change data to Apache Kafka consumers. The Stelo-provided Streaming Support may be associated with an incremental group containing one or more subscriptions. Acting as a Kafka Producer, it injects a message for each subscribed table’s activity, with one message for each Insert, Update and Delete DML operation. While each group may be associated with only one producer; multiple groups may be configured to use different producers which may also share common source tables. No customization of the producer code is required to use the functionality.
Prerequisites
- SQDR Plus 6.20 and SQDR 6.20
Note: Both SQDR Plus and SQDR must reside on the same system. - DB2 LUW 11.5.5 or later
- The connectivity information of the Confluent environment must be known in advance prior to setting up streaming to Confluent. To gather the required connectivity information, please refer to Setting up the Confluent environment for more details.
Creating the Destination
1. Right-click on Destinations and select Insert Destination
2. Select ODBC Driver, then search for the StarSQL driver and select. Once the driver has been selected, enter the following connection string
HostName=127.0.0.1;Port=50000;Server=SQDRC;IsolationLevel=2;PkgColID=SQDR
3. Enter the credentials of the sqdr user and then select the Advanced tab. The connection will be successful if the Advanced panel is viewable.
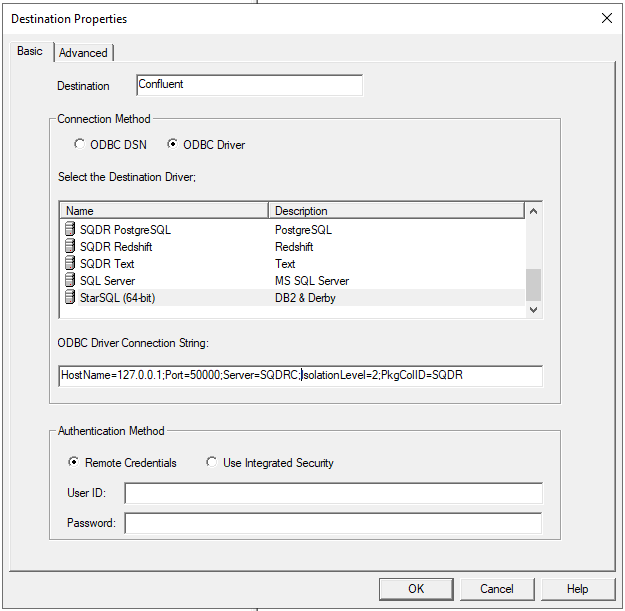
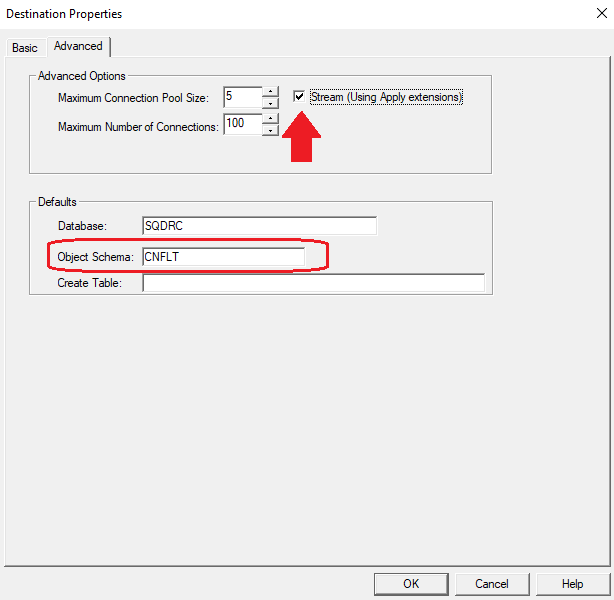
4. On the Advanced panel of the destination, select the checkbox Stream (Using Apply Extensions) and set the Object Schema to CNFLT.
Creating the Incremental (I/R) Group
1. In the Data Replicator Manager, right-click on Groups, then select Insert Incremental Group.
2. Enter the desired name of the I/R group, then select the Advanced tab
3. In the Advanced tab, select the Source to replicate data from and the destination that was created in the previous section.
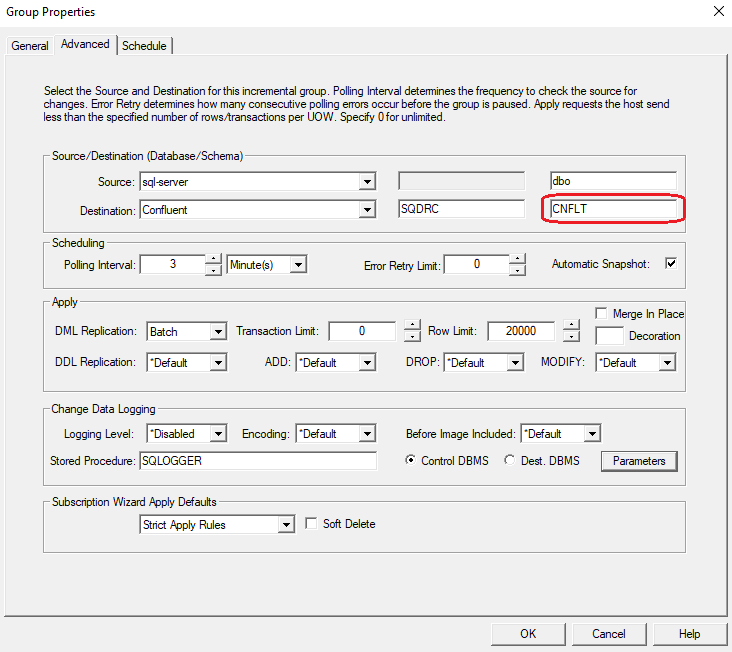
4. Select parameters. Take the parameters that were gathered in the Setting up the Confluent environment article and insert them into the Parameters Panel as shown below
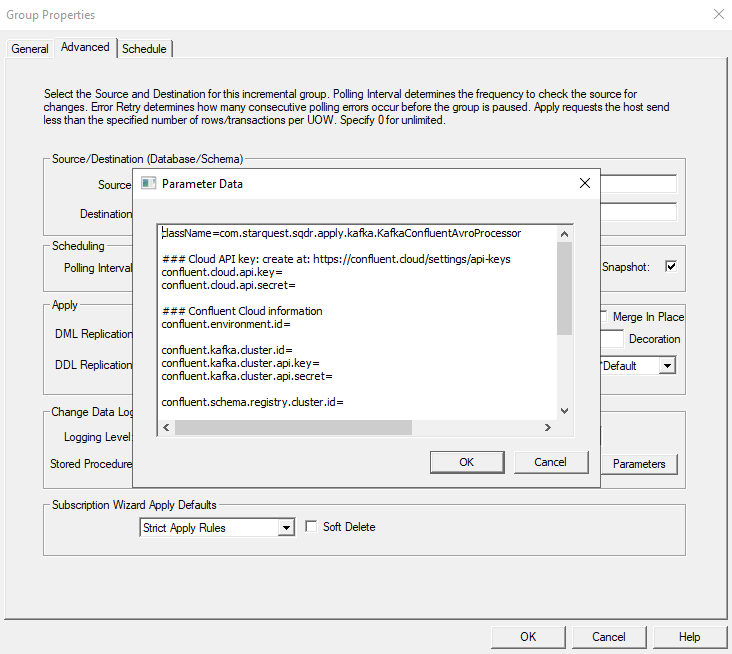
Note: The Confluent parameters may differ depending on if the environmet is Confluent Cloud or Confluent Platform.
Creating the Incremental (I/R) Subscription(s)
1. Expand the I/R group that was created. Right-click on Members, then select Insert Member
2. Enter the Object Schema (Source Schema) and the desired Object Name (Source table(s)). Select Refresh and a list of tables based on the values entered in the Object Schema and Object Name will appear.
Note: A wildcard (%) can be used to display a list of table(s) that match a particular pattern. Select a list of table(s) to be exported, then select Export. This will export the list of table(s) to a text file.
3. Select next. When creating the subscription(s), specify the following properties in the Destination panel down below. All other properties can be kept in their default values.
- Destination DDL Options - Create every time subscription is saved
- Baseline Replication Options - Null synchronization - DDL Only
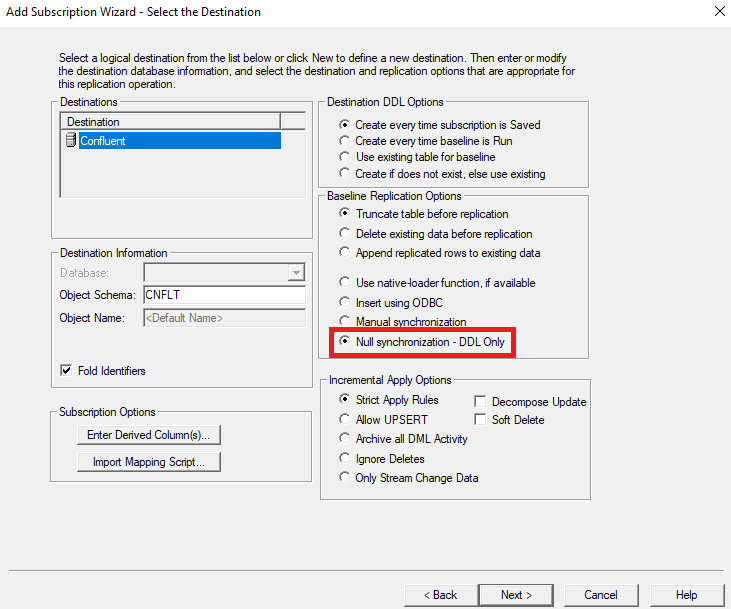
4. Continue through the Subscription Wizard with the default values
5. Once the subscription(s) have been created, right-click on the I/R group and then select Run Group
Note: The subscription(s) will run automatically if Automatic snapshot has been enabled for the I/R group.
6. Verify the that topic(s) have been created along with their corresponding schema(s) in the Confluent Cloud dashboard.
7. (Optional) Once the topics have been created, users can create a sink connector to their destination database(s) of interest. Please see the following links down below for configuring the following to go to Confluent:
- Google Cloud BigQuery Sink Connector
- SnowFlake Sink Connector
- JDBC Sink Connector(s)
For an additional list of supported Confluent Cloud connectors, refer to Confluent Cloud Connectors for more details
For an additional list of supported Confluent Platform connectors, refer to Confluent Platform Connectors for more details
8. In the Confluent dashboard, after verifying that the topic(s) and schema(s) of interest have been created, delete all of the subscription(s) in the I/R group
Repeat steps 1 - 5 to recreate the subscription(s). However, upon step 3 change the Baseline Replication Option from Null Synchronization - DDL Only to Use native-loader function
Troubleshooting
- Verify connectivity to the Confluent environment by running the following commands
Command Line
telnet <host> <port>
PowerShell command
Test-NetConnection -ComputerName <host> -Port <port>
- The following error may appear in db2diag.log or an error message when an invalid hostname or IP address is supplied in Parameters.
No resolvable bootstrap urls given in bootstrap.servers
Hints and FAQ
Question: The statistics for the subscription show that rows have been sent, but I do not see them in my destination.
Answer: The statistics represent the number of rows that have been sent to Kafka; SQDR does not typically have visibility into the activity on the final destination. Make sure that the Consumer is running and performing its task. If the Consumer is not running, the data is typically retained by the Kafka server or Azure Event Hub if it has been configured for retention.
DISCLAIMER
The information in technical documents comes without any warranty or applicability for a specific purpose. The author(s) or distributor(s) will not accept responsibility for any damage incurred directly or indirectly through use of the information contained in these documents. The instructions may need to be modified to be appropriate for the hardware and software that has been installed and configured within a particular organization. The information in technical documents should be considered only as an example and may include information from various sources, including IBM, Microsoft, and other organizations.