
Stelo Technical Documents
Using SQDR with Google BigQuery
Last Update: Nov 28 2023
Product: StarQuest Data Replicator
Version: SQDR 6.30 or later
Article ID: SQV00DR054
Abstract
Google BigQuery is a managed data warehouse, and is part of the Google Cloud Platform.
SQDR can be used to replicate snapshot and incremental data from any supported database to BigQuery.
The technical document describes the recommended technique of
- Using the Simba BigQuery ODBC driver running on Tier 3 to configure the subscription and create the destination table (or to perform column matching in the case of using an existing table).
- Configuring the subscription to transmit the data (both baseline and incremental changes) directly from Tier 2.
Prerequisites
- SQDR and SQDR Plus 6.30 & later; combined tier environment (i.e. both tiers residing on the same system).
- The control database for SQDR should be a local IBM Db2 LUW database named SQDRC, with control tables located in the schema SQDR (i.e. default configuration). The use of Microsoft SQL Server or remote control databases is not currently supported.
- A Google Cloud account with BigQuery capabilities.
- Network connectivity from the SQDR system to Google Cloud.
- Verify that the password is known for the Windows user sqdr.
Considerations
- BigQuery has a 10 MB message limit which determines how many rows can be stored within the message. However, if a table has a column that contains a huge size greater than 10 MB, then the Stelo Capture component will attempt to find the best way to truncate the data for the data in those BLOB column to fit within the message. The user can set the maximum BLOB length of the column to fit within the 10 MB message size. As an example, if the table contains 5 BLOB columns each 2 MB in length, the user can set the maximum BLOB length to be less than 2 MB so that the data can be sent to BigQuery. Adjust the I/R group parameters maxBlobLength and/or maxClobLength accordingly. For more information, refer to I/R group parameters for more information.
Solution
Google BigQuery Setup
Create a Project and Dataset
- Logon to the BigQuery SQL Workspace at https://console.cloud.google.com/bigquery
Create a project if necessary, or select an existing project from the dropdown in the upper left:
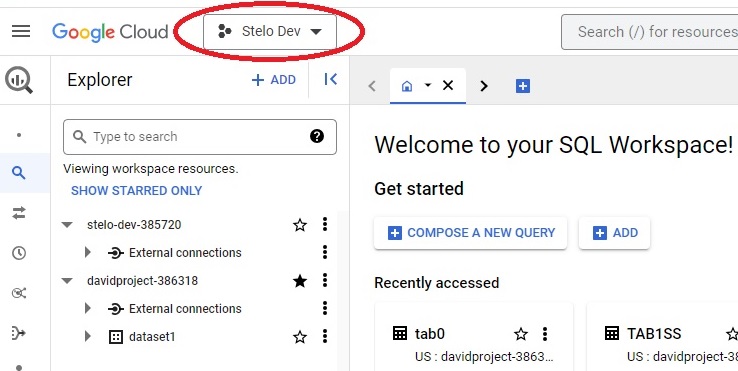
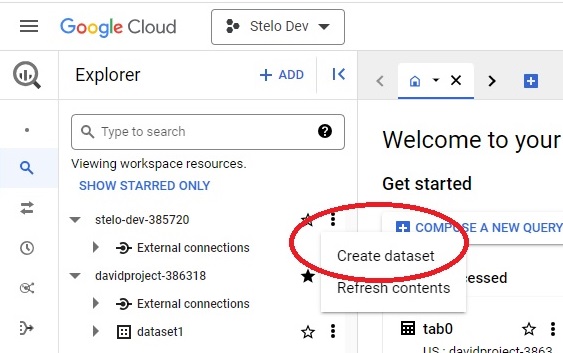
- If necessary, create a dataset by clicking the 3 vertical dots next to the project name and selecting Create dataset.
Create a Google Cloud Service Account
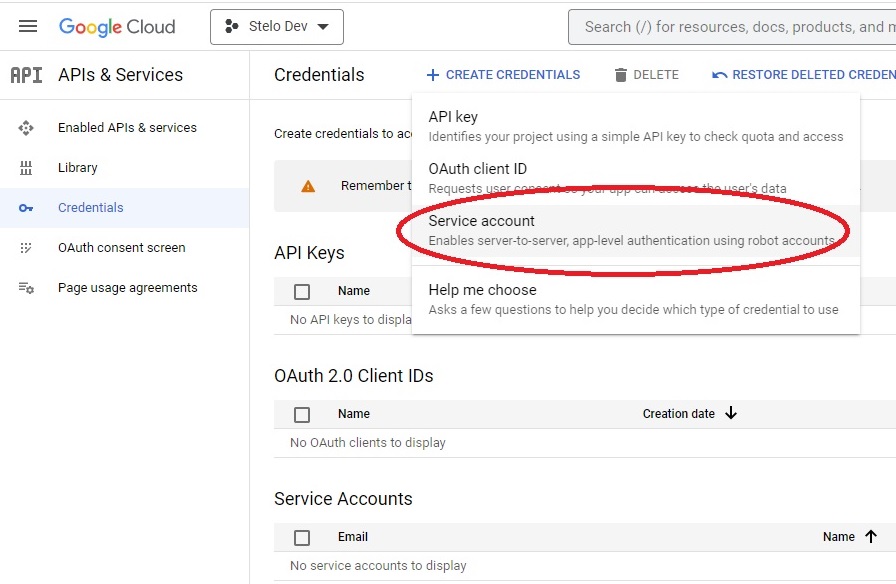
- Open https://console.cloud.google.com/apis/credentials
- Click +Create credentials and select Service Account from the dropdown
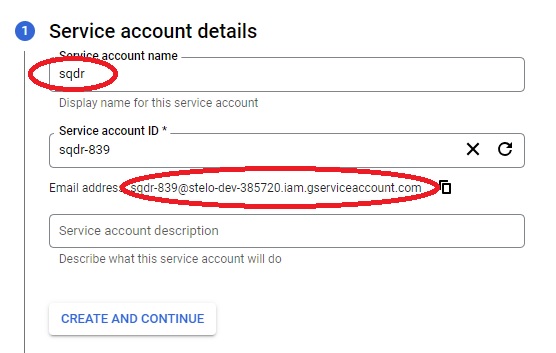
- Enter a value (e.g. sqdr) for Service account name. The Service account ID will be autogenerated.
- Record the email address that appears below the Service Account ID by selecting the copy icon next to the email address to copy it to the clipboard.
- Click CREATE AND CONTINUE
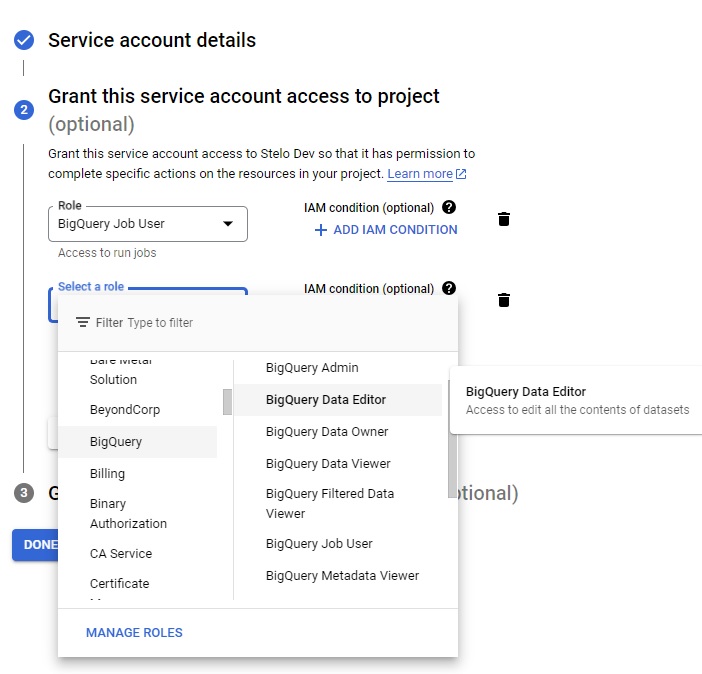
- Under Service account details/Grant this service account access to project, grant the following roles from the dropdown:
- BigQuery Job User
- BigQuery Data Editor
- BigQuery Job User
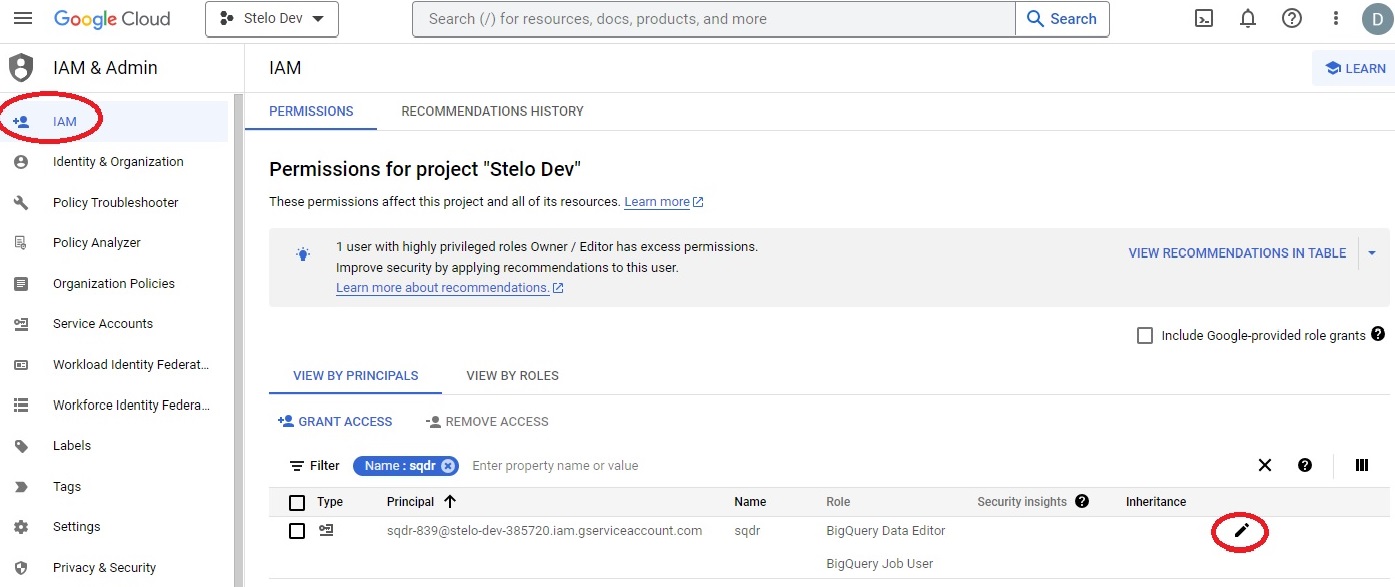
If the roles need to be changed for the service account, select IAM from the left column, and select the Pencil icon next to the name of the Service Account.
Create JSON file containing credentials
- Next create a JSON file containing credentials at https://console.cloud.google.com/apis/credentials.
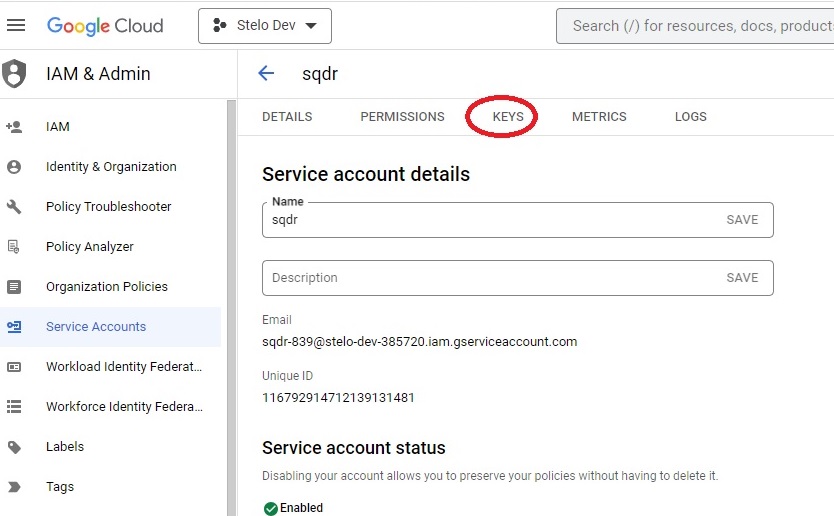
- Select the service account.
- Select Keys from the menu.
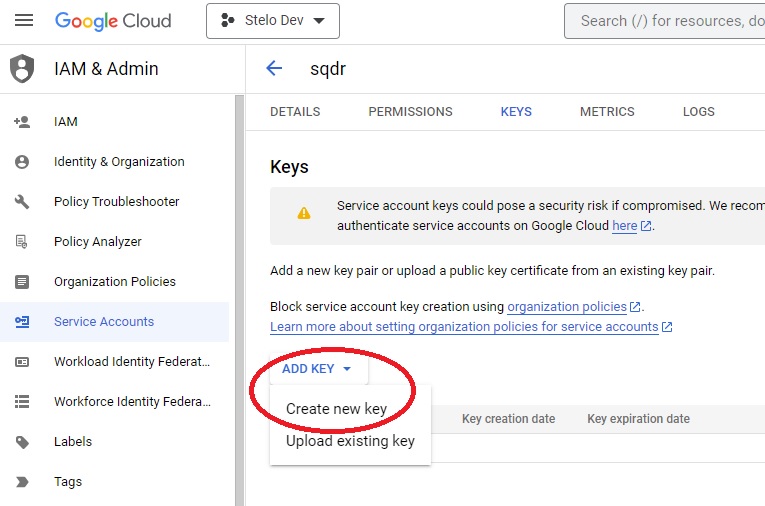
- On the next screen, select Add Key and choose Create new key from the dropdown:
- On the create private key dialog, choose JSON and select CREATE

This will create a JSON file that will be used by SQDR. Save the file and transfer it to the SQDR machine.
We recommend creating a directory gbq in C:\ProgramData\StarQuest\sqdrplus (/var/sqdrplus/gpq on Linux) and placing the JSON file there.
Note that private keys for service accounts do not typically expire.
SQDR Configuration
Creating an SQDR destination using the Simba ODBC driver
The Simba ODBC driver is used by Data Replicator Manager to configure the subscription and create the destination table. Or, in the case of using an existing destination table, it is used to perform column data type mapping. The actual data transfer (both baseline and incremental updates) is handled by the streaming support of Tier 2.
- Download the Simba BigQuery ODBC driver as supplied by Google.
- Install the driver
- Compose the ODBC connection string. It will look something like this, replacing the Catalog, Email, and KeyFilePath values with the actual values of your service account, service account email, and full path to the JSON file containing the private key.
Catalog=stelo-dev-385720;
Email=sqdr-839@stelo-dev-385720.iam.gserviceaccount.com; KeyFilePath=C:\ProgramData\StarQuest\sqdrplus\gbq\stelo-dev-385720-d5ad27ad01e9.json;
OAuthMechanism=0;EnableSession=1 - Create a destination in Data Replicator Manager, paste in the connection string as above, and choose Integrated Security.
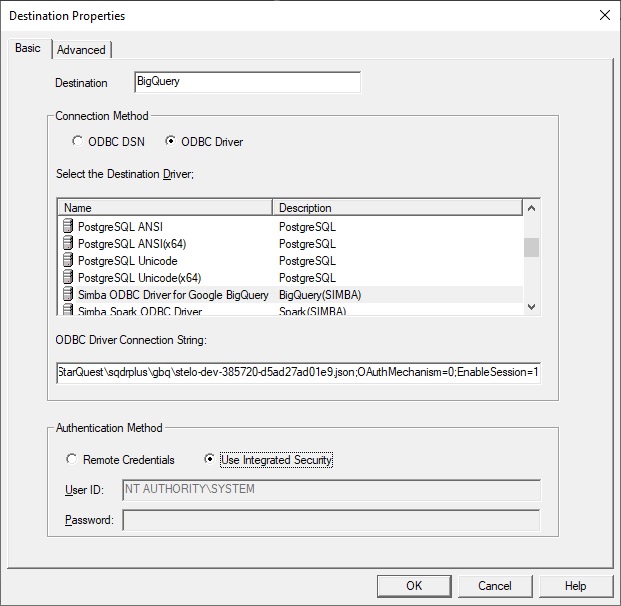
- On the Advanced panel of the Destination, change the default schema on the Advanced panel from SYSTEM to the name of the BigQuery dataset.
- Select the checkbox Stream(Using Apply extensions) and optionally specify a directive for to be appended to the Create Table.
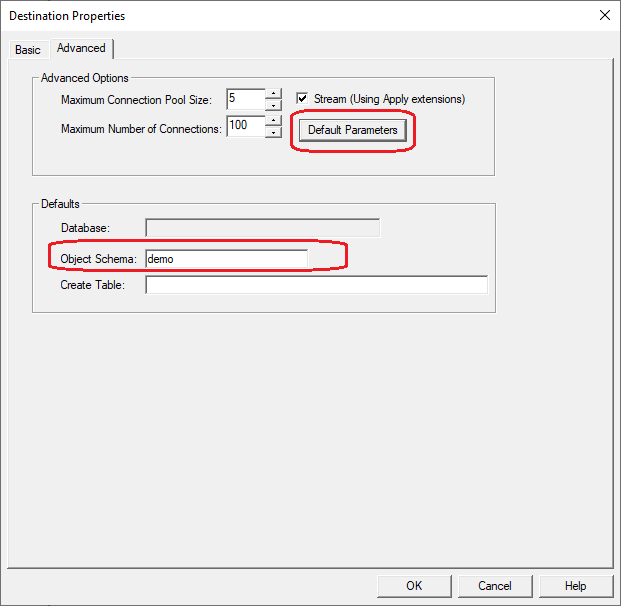
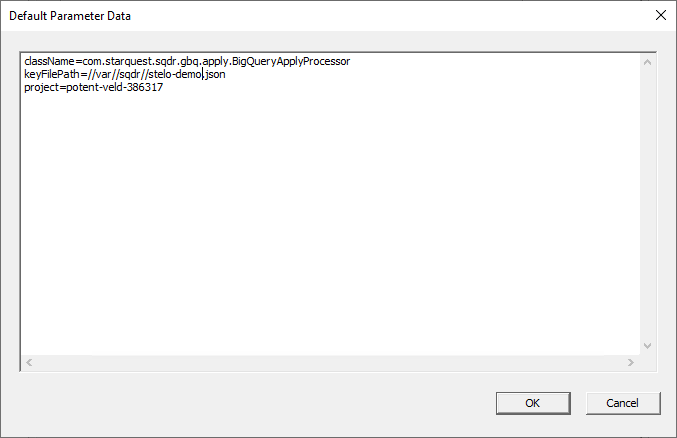
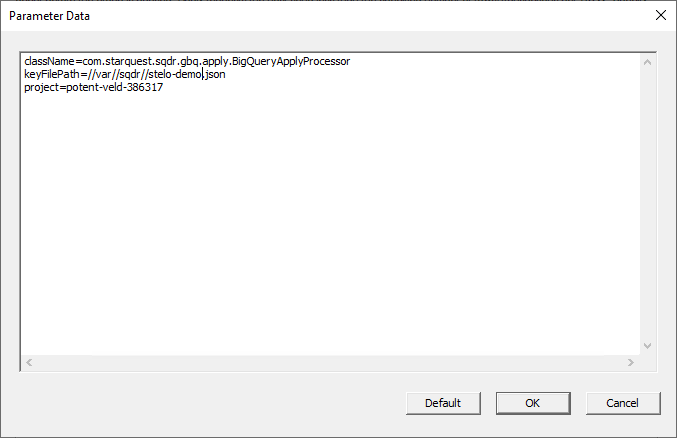
- Set the default parameters in the Default Parameter Data dialog as shown below, enter the following information, replacing the project and JSON filename with your values.
Windows
className=com.starquest.sqdr.gbq.apply.BigQueryApplyProcessor
keyFilePath=C:\\ProgramData\\StarQuest\\sqdrplus\\gbq\\stelo-dev-385720-d5ad27ad01e9.json
project=stelo-dev-385720
Linux
className=com.starquest.sqdr.gbq.apply.BigQueryApplyProcessor
keyFilePath=//var//sqdr//stelo-user.json
project=stelo-dev-385720
Configuring the SQDR Incremental Group
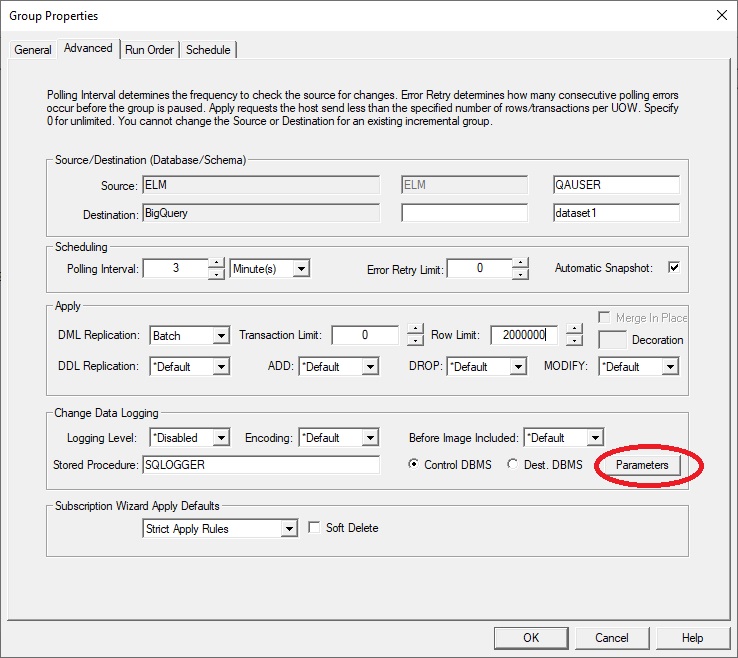
- Create an Incremental group, specifying the desired Source and Destination.
- (Optional) If the user wants to create a group with parameters that are different from the default, select the Parameters option of the Advanced dialog of the incremental group. From there, enter the modified parameters as required.
Creating a Subscription
-
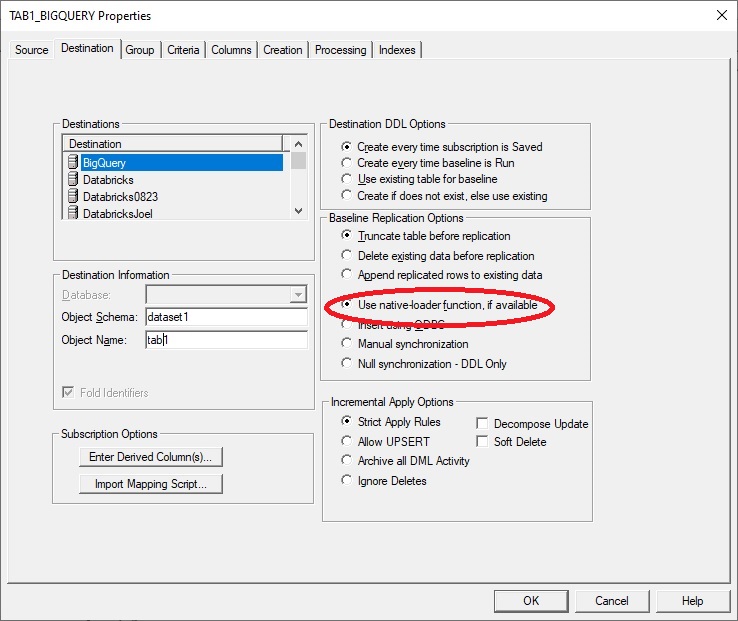
If the goal is incremental change data only, then configure the destination panel of the subscription specifying Baseline Replication Options to Append replicated rows to existing data and Null synchronization - DDL only as shown here. The destination panel should be configured as Insert using ODBC.
OR
If you want baselines to be performed using the Tier 2 Streaming Support, specify Baseline Replication Options as Truncate or Append replicated rows (as desired) and Use native-loader function.
- After creating the subscriptions, if Automatic Snapshot (on the advanced panel of the group) is enabled (default), the group is run automatically after creating the subscriptions.. Otherwise, enable capture & apply.by running the subscriptions or the group.
Reference
Agent Parameters
Though the setup/configuration for this feature is typically done in Data Replicator Manager (Tier 3) as described in this technical document, there may be advanced agent properties that can be used to adjust the behavior of the agent. See the Configuration Reference topic (under Reference and Troubleshooting) of the SQDR Plus help for details.
- parallelApply - default is false. This configuration parameter can be used to control how many tables the replicator is applying changes for in parallel onto the BigQuery destination. The level of parallelism is control by the Concurrency: Maximum Subscriptions property of the I/R group.
I/R Group Parameters
- (Required) className - Always set to com.starquest.sqdr.gbq.apply.BigQueryApplyProcessor to enable replication to BigQuery.
- (Required) keyFilePath - The file path on the Stelo server where the Stelo Apply and the Stelo Capture components will read the service account JSON file. Depending on the OS, the value of this variable may need to be set accordingly. See the following for examples on how to set this variable:
Windows
C:\\some\\path\\to\\service-account.json
Linux
//some//directory//to//service-account.json
- (Required) project - The BigQuery project where we will be replicating to.
- (Optional) mergeSchema - This parameter can be used to set the staging tables in a different schema (dataset) asides from the destination schema set in the subscription(s).
- (Optional) maxBlobLength - Can be used to set the maximum BLOB length of a column.
- (Optional) maxClobLength - Can be used to set the maximum CLOB length of a column.
Troubleshooting
Issue:
Note that table names in BigQuery are case-sensitive. SQDR can be used to use lower case for destination table names by unchecking Fold Identifiers on the Destination panel of the subscription.
Derived Columns
When specifying derived columns, we recommend using an Expression (the upper left field of the Derived Column dialog) that is acceptable for Db2 LUW.
In the typical scenario of handling both baselines and incremental changes though Tier 2, all derived columns are processed in the Db2 LUW staging database rather than at the Source.
Specifying different expressions in the Expression field (source database) and Staging Expression field (Db2 LUW staging database) is only applicable when baselines are obtained directly from the Source by Tier 3 i.e. when the Destination panel of the subscription specifies Insert Using ODBC rather than Use Native Loader Function. This method is not recommended.
DISCLAIMER
The information in technical documents comes without any warranty or applicability for a specific purpose. The author(s) or distributor(s) will not accept responsibility for any damage incurred directly or indirectly through use of the information contained in these documents. The instructions may need to be modified to be appropriate for the hardware and software that has been installed and configured within a particular organization. The information in technical documents should be considered only as an example and may include information from various sources, including IBM, Microsoft, and other organizations.