
Stelo Technical Documents
SQDR Plus Product FAQs
Last Update: 25 November 2022
Product: SQDR Plus
Version: 4.50 & later
Article ID: SQV00PL013
Abstract
This article answers frequently asked questions (FAQs) about the StarQuest Data Replicator Plus (SQDR Plus) data replication solution. For a general overview of the SQDR solution and real time data replication, see the SQDR product page. Also see SQDR FAQs for additional questions and answers about database replication and data replication tools.
Questions
- Open Source and Proprietary Technologies used by StarQuest SQDR/SQDR Plus
- Performance impact on the Db2 for i Source (Tier 1) System
- Performance impact on the SQL Server Source (Tier 1) System
- Coexistence with High Availability Products
- Recommendations for creating target tables for use with a specific application
- Why SQDR Plus uses IBM Db2 for LUW for the Staging Database
- Tier 2/3 (middle tier) Server Sizing Recommendations
- Tier 2 disk space questions
- Licensing
- Can SQDR replicate a Materialized View?
- Recovery in the case of loss of network connectivity or server availabililty
Answers
Question: What open source and proprietary technologies are used by the StarQuest SQDR/SQDR Plus replication solution?
Answer:
- Tier 1 – Source database: no additional technologies installed.
Exception: when replicating from a IBM Db2 for LUW source, we recommend using the Log Reader Stored Procedure provided by Stelo. This may require the installation of Microsoft Visual C++ Redistributables (for Visual Studio 2015-2022) if it is not already present.
- Tier 2 – SQDR Plus Staging system:
Open Source technologies:- JETTY application server (Eclipse Foundation)
- Derby database (Apache)
- JTOpen (IBM Toolbox for Java – Sourceforge.net)
- opencsv (Apache)
- MySQL Binary Log connector (mysql-binlog-connector-java)
- HSQLDB (hsqldb.org)
- Kafka (Apache)
- JETTY application server (Eclipse Foundation)
Proprietary (no-charge) technologies:Proprietary (licensed) technologies:
- OpenJDK JRE 1.8 or 17
- Microsoft JDBC Driver for SQL Server (provided by Stelo under license by Microsoft)
- Oracle JDBC Driver & Instant Client (Oracle)
- Informix JDBC Driver (IBM)
- MySQL JDBC driver (mysql-connector-jdbc)
- IBM Db2 LUW (provided by Stelo under license by IBM)
All except IBM Db2 LUW are included in the SQDR Plus installer.
- Tier 3 - SQDR
- Microsoft SQL Server for SQDR control database – e.g. SQL Server Express Edition (2012 or later), and the appropriate level of .NET Framework required by SQL Server.
- OR IBM Db2 LUW for SQDR control database
- Suitable ODBC drivers for access to the Source (Tier 1) and Destination (Tier 4) databases
StarSQL (for Db2 access) and SQDR Bundled ODBC drivers for various databases (Oracle, Informix, Postgres, Salesforce, Redshift, etc.) are included in the SQDR installer.
Other drivers are installed as needed e.g. IBM i Access Client Solutions, Microsoft ODBC 17 for SQL Server, Oracle Instant or Full Client and ODBC Driver, Informix Client SDK, MySQL Connector/ODBC Driver, MariaDB ODBC driver, PostgreSQL psqlodbc driver, Snowflake ODBC driver.
- Tier 4 – Destination DBMS: no technologies required/installed
Question: What performance impact does SQDR Plus have on the Db2 for i source (Tier 1) system? Our source database is around 100GB. Do you think that a database replication of this size will create performance problems on the source machine? Our Db2 admin says that searching in journals can cause performance issues.
Answer: The size of the database is only relevant when the initial copy is made. The relevant issue for ongoing performance is the volume of changes; for instance, a 1TB database might only have 1Kb changes per day. During the process of acquiring the 100GB of initial data a modest load will be present. Once the tables are copied, the only interaction is with the journal receivers.
Db2 for i source: SQDR Plus has minimal impact on the Db2 for i source system because the processing of the journal entries (the "change data") is transferred directly from the IBM i receivers through the network to the Tier 2 processing. No additional processing is performed on the IBM i system beyond reading the journal entries and placing them into a shared memory object, which is then transferred using a protocol much like FTP.
We believe that our technology imposes less overhead than any other solution in the marketplace.
Question: What impact (performance and storage) does Change Tracking (used by SQDR Plus) have on the SQL Server source (Tier 1) system?
Answer: See the Understanding Change Tracking Overhead section of the Microsoft document Manage Change Tracking (SQL Server).
In regards to performance:
Change tracking has been optimized to minimize the performance overhead on DML operations. The incremental performance overhead that is associated with using change tracking on a table is similar to the overhead incurred when an index is created for a table and needs to be maintained.
Also review the section Effects on Storage.
Question: Does SQDR Plus coexist with High Availability (HA) products such as Vision Solutions MIMIX, IBM DataMirror, IBM Infosphere CDC, Trader's QUICK-EDD, and MaxAVA HA?
Answer: Yes - SQDR Plus uses only standard IBM i commands and APIs to interact with the journal receiver and will not interfere with other applications. We have numerous customers using SQDR Plus with these HA products. The main issue customers have is deciding if they want to use *AFTER only imaging - this decision forces SQDR to be exposed to reorgs.
Question: We will be using SQDR Plus to replicate Oracle JD Edwards EnterpriseOne data from Db2 to SQL Server. I have the ability to pre-generate the tables and indexes in the target (SQL Server) database using a JD Edwards-specific application, assuring that the tables are compatible with the JD Edwards applications. Is this a viable approach or would it be best to let SQDR handle the table/index creation?
Answer: We encourage customers to configure SQDR to create the destination tables on the SQL Server. In part this is to insure the proper mapping of change data captured on the IBM i system and the destination table. Also, if the Customer's HA software utilizes *AFTER images only for capturing change data, then the SQDR Plus software must rely upon a synthetic column (the Relative Record Number or "RRN") to uniquely identify the row in the destination table, and It is unlikely that the JDE tool would provide this column. Therefore it is best to allow SQDR to create the destination including this column for each table. Alternatively, if the HA software configures *BOTH images in the journals then we can dispense with the RRN column and just utilize any unique index (including a primary key) to identify rows.
Another issue that should be addressed in the planning stage is the use of Unicode datatypes on the destination SQL Server. We strongly encourage customers to use NCHAR/NVARCHAR data-types for SQL Server as this provides the greatest fidelity when mapping data from IBM i EBCDIC to Windows and other non-EBCDIC environments.
Our recommendation is to allow SQDR to create the tables and exploit UNICODE data-types, and use the tool to create any additional indexes.
Question: Why does SQDR Plus use IBM Db2 LUW for the staging database for SQDR Plus?
Answer: We use Db2 because it supports a superset of the data types used on Db2 for i and other source databases, and because of its strong Java support. The database should be considered as embedded and for exclusive use of the data replication software. Normally the customer has no direct interaction with the database software.
Question: Do you have any recommended hardware specifications for the SQDR Plus/SQDR server?
Answer: Here are the hardware recommendations for the SQDR Plus/SQDR "middle tier”. Many customers use a virtual platform such as VMWare ESXi.
- Windows Server 2022/2019/2016 with latest Windows updates applied.
- The PoC (proof of concept) system should be dedicated to the SQDR application.
- Antivirus should be either not installed, or disabled for specific locations (C:\Program Data\StarQuest; C:\Program Data\IBM; S:\DB2; L:\DB2)
- A High Speed Network Adapter (typically 1Gbs Ethernet, etc.)
- Hyper-Threading should be enabled if available.
- We recommend using high speed storage (SSD) for the database and log partitions.
- 3 disk partitions of sizes listed below. C: is used for the operating system and applications; S: is used for the built-in staging database, and L: is used for the logs of the staging database.
“Entry Level System” < 1 M TPH; < 1K subscriptions:
- 2 cores, minimum 2.4 Ghz frequency; 8GB of RAM
- 3 disk partitions: 50gb ;50gb ;50gb (C:; S:; L:)
“Standard System” 1-10M TPH; 1K to 5K subscriptions:
- 2 cores, 2.67Ghz frequency; 16GB of RAM
- 3 disk partitions: 50gb ;100gb ;50gb (C:; S:; L:)
“Enterprise” > 10M TPH; > 5K subscriptions:
- 4 cores, minimum 3.0 Ghz; 64GB of RAM
- 3 disk partitions: 50gb; 200gb; 100gb (C:; S:; L:)
*TPH = Transactions/Hour
Question: Regarding disk space, how large the control database will grow? Does it need to be as large as the entire source or target data set or just as large as the largest table?
Answer: The size of the Db2 staging database is related to the number of tables to be monitored, and the number of changes to be staged at any given time. It is not related to the size of any source table.
Question: How is SQDR licensed?
Answer:
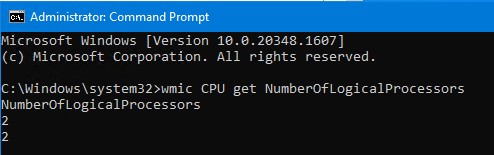
Our licensing is based on the number of virtual (logical) cores allocated to the Windows or Linux VM. This applies regardless of whether hyperthreading is enabled or not. To determine the core count, we use these commands:
On Windows: run the command 'wmic CPU get NumberOfLogicalProcessors' and sum all the logical cores across all processors. This example indicates the total core count of 4 (four):
On Linux: run the command 'lscpu | grep "^CPU(s):" | awk '{print $2}'. For example:

Question: Can SQDR replicate a materialized view?
Answer:
SQDR may be used to replicate the data in a materialized view as a "snapshot" replication.
Incremental replication of a materialized View is not recommended. The overhead of source changes for materialized views generally makes such objects poor candidates for real-time replication. In general, all rows tend to be regenerated, producing high levels of log activity. Teal-time replication of an entire table tends to run slower by at least one order of magnitude, as all real-time operations are performed one row at time, precluding any batch update optimizations that a full snapshot replication may leverage.
Our recommendation is to replicate the underlying tables of the view in real-time, and build the material views on the destination tables. This is generally the most satisfactory result.
Question: how does SQDR handle recovery in the case of loss of connectivity to the source or target database i.e. server or network disruption?
SQDR real time replication uses an active monitoring/retry design that decouples the need to maintain active connections from and to the source and destination databases.
This decoupled approach uses checkpoint/restart technique that relies upon the ability to precisely identify the last known transaction detail (on the source system) when the source connection is lost. Upon resumption of the source connection (which is automatically retried until success) the SQDR process automatically repositions and continues from the last known checkpoint for the logs (i.e. the source of change data.)
With respect to the destination database – SQDR uses database commit/rollback transaction control, so that a sharp boundary is always available upon restart to continue from the last commit point. Again, the connection to the database is constantly retried after the loss of connection, so no operator involvement is required to resume replication.
DISCLAIMER
The information in technical documents comes without any warranty or applicability for a specific purpose. The author(s) or distributor(s) will not accept responsibility for any damage incurred directly or indirectly through use of the information contained in these documents. The instructions may need to be modified to be appropriate for the hardware and software that has been installed and configured within a particular organization. The information in technical documents should be considered only as an example and may include information from various sources, including IBM, Microsoft, and other organizations.