
Stelo Technical Documents
Using SQDR Streaming Support with Azure Databricks
Last Update: 29 December 2022
Product: StarQuest Data Replicator
Version: SQDR 6.11 or later
Article ID: SQV00DR049
Abstract
SQDR Streaming Support provides a mechanism to apply incremental change data from legacy DBMS systems (such as IBM Db2, Oracle, Microsoft SQL Server, MySQL and Informix) into new generation data engines using Apache Kafka, an open-source message broker project that provides a unified, high-throughput, low-latency platform for handling real-time data feeds.
Azure Event Hubs is a Kafka-compatible cloud-based streaming service. Apache Spark is an open-source unified analytics engine for large-scale data processing, and Azure Databricks is a fully managed Apache Spark environment hosted in the Azure environment.
This technical document describes the steps needed to configure Azure Event Hubs and Azure Databricks to receive and apply the incremental changes from SQDR into Delta Lake storage.
In addition, the Simba Spark ODBC driver (provided by Databricks) can be used to create the target table.
Baseline data (if desired) can be handled either by Kafka messages sent to Databricks using Event Hubs (recommended) or by the Simba Spark ODBC driver.
See SQDR Streaming Support for an overview and instructions for configuring SQDR to deliver incremental changes to a customer-written Kafka Consumer through Apache Kafka, Azure Event Hubs, or other Kafka-compatible services.
See Using Stelo Data Lake Sink Connector for Azure Databricks for an alternate method of performing the same task of transferring data via SQDR to Data Lake storage, using JDBC rather than Event Hubs. This method requires JDBC connectivity to the SQDR staging database (e.g. via VPN) but is likely to offer better performance and a simpler configuration.
Prerequisites
- SQDR and SQDR Plus 6.11 & later; combined tier envrionment (i.e. both tiers residing on the same system).
- The control database for SQDR should be a local IBM Db2 LUW database named SQDRC, with control tables located in the schema SQDR (i.e. default configuration). The use of Microsoft SQL Server or remote control databases is not currently supported.
- You will need an Azure account to which you can add Databricks support.
Overview
- Event Hub Setup
- Databricks Setup
- Databricks Notebook Setup
- Creating an SQDR destination using the Simba ODBC driver
- Configuring SQDR incremental group
- Creating a Subscription
- Troubleshooting
- Hints & FAQ
Event Hub Setup
Create an Event Hubs Namespace and an Event Hubs Instance
Sign on at the Azure portal
https://azure.microsoft.com/en-us/features/azure-portal/
Access the Event Hubs dashboard by entering Event Hubs in the Search bar.
Create an Event Hubs Name Space. In our example, we created qanamespace.
- Pricing Tier - Standard or higher (this is required if you want message retention)
- Connectivity method: Public access
Create an Event Hubs instance (this is equivalent to a Kafka topic, which is equivalent to an SQDR I/R group). Note an Event Hubs instance may be automatically created if it does not already exist when a Kafka Producer or Consumer connects (assuming the connection has sufficient rights), but in our example we will create it here.
While viewing the Namespace, select + Event Hub

Configure:
- Partition count. We recommend starting with 1 for initial functional testing and increasing later if needed for performance.
- Message retention. We recommend starting with 1 (day) and increasing later if necessary.
- There is no need to enable Capture - this will be handled by Databricks.
Obtain the connection string
You can use the connection string for either the Event Hubs Namespace or the individual Event Hubs Instance. In our example, we will use the Event Hubs Instance.
For the individual Event Hubs Instance
- Select Settings/shared access policies
- Click + Add to create a policy
- Name the policy and choose capabilities (Manage/Send/Listen). For our purpose, Send & Listen are sufficient.

Once the policy is created, select it and copy the Connection string–primary key

A typical connection string will look like:
Endpoint=sb://qanamespace.servicebus.windows.net/;
SharedAccessKeyName=qahub1_policy;
SharedAccessKey=gGKrXXXXu4wT11VIRebtm6cXXXX1uogZbXxlUSvwu8U=;
EntityPath=qahub1
The information in the connection string will be used in two places:
- In the Parameters dialog of the Advanced panel of the incremental group - i.e. instructing SQDR how to connect to the Event Hub as a Kafka producer.
- In the Scala code in a Databricks notebook, acting as a consumer.
To obtain the connection string for the Event Hubs name space:
- Select Settings/shared access policies
- Choose the existing policy RootManageSharedAccessKey
- Copy the Connecting string-primary key from the right panel
Databricks Setup
- Access the Azure Databricks Service by entering Databricks in the Search dialog.
- Create a Databricks workspace:
- Select the Pricing Tier
- On the Networking panel, you can choose the type of networking. In our case, we left both choices at the default of No (No Secure Cluster Connectivity = Public IP; no Virtual Network)
- Select the Pricing Tier
- Go to the Databricks resource and Launch the Workspace. Sign in to Databricks if necessary.
- Select the Compute icon in the left column to access clusters.
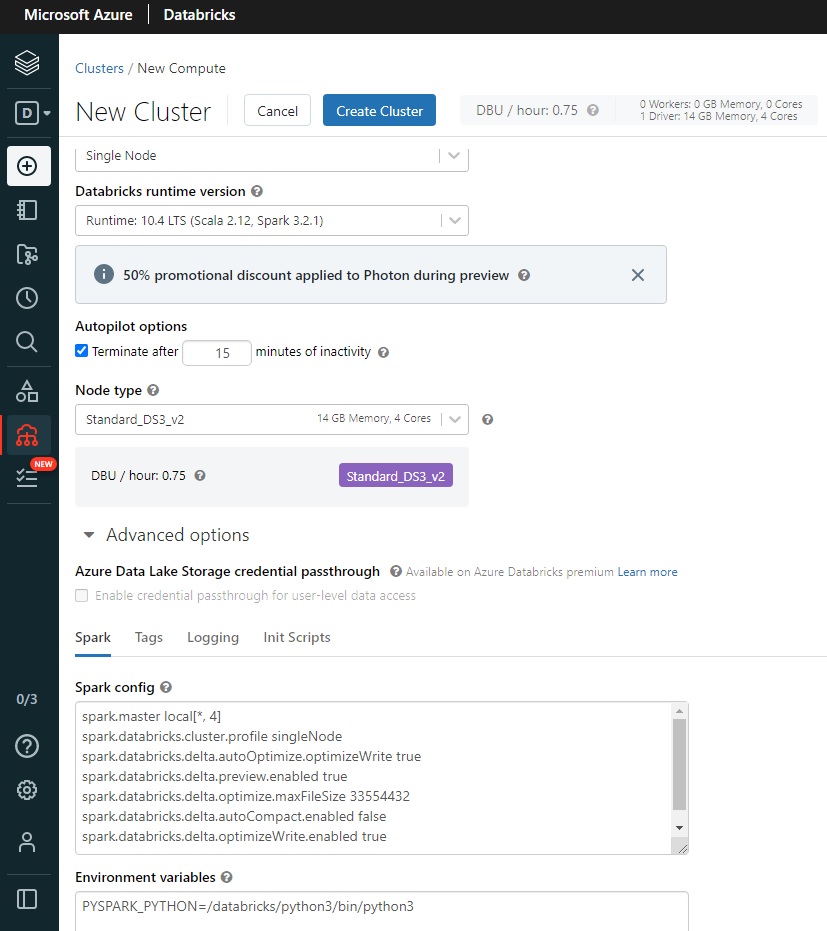
- Create a cluster and specify its characteristics. For functional testing (when performance is not necessarily a concern), you can create a minimal cluster:
- Cluster mode: single node
- Choose a Databricks runtime version e.g. 10.4 LTS (Scala 2.12, Spark 3.2.1)
- Terminate after 15 minutes of inactivity (default 120)
- Standard_DS3_v2
- Cluster mode: single node
- You can enter additional configuration options in the Spark Config field under Advanced Options. The following options have been suggested to improve performance of the Scala code, but have not been verified:
spark.databricks.delta.autoOptimize.optimizeWrite true
spark.databricks.delta.preview.enabled true
spark.databricks.delta.optimize.maxFileSize 33554432
spark.databricks.delta.autoCompact.enabled false
spark.databricks.delta.optimizeWrite.enabled true
Creating the cluster takes about 5 minutes.
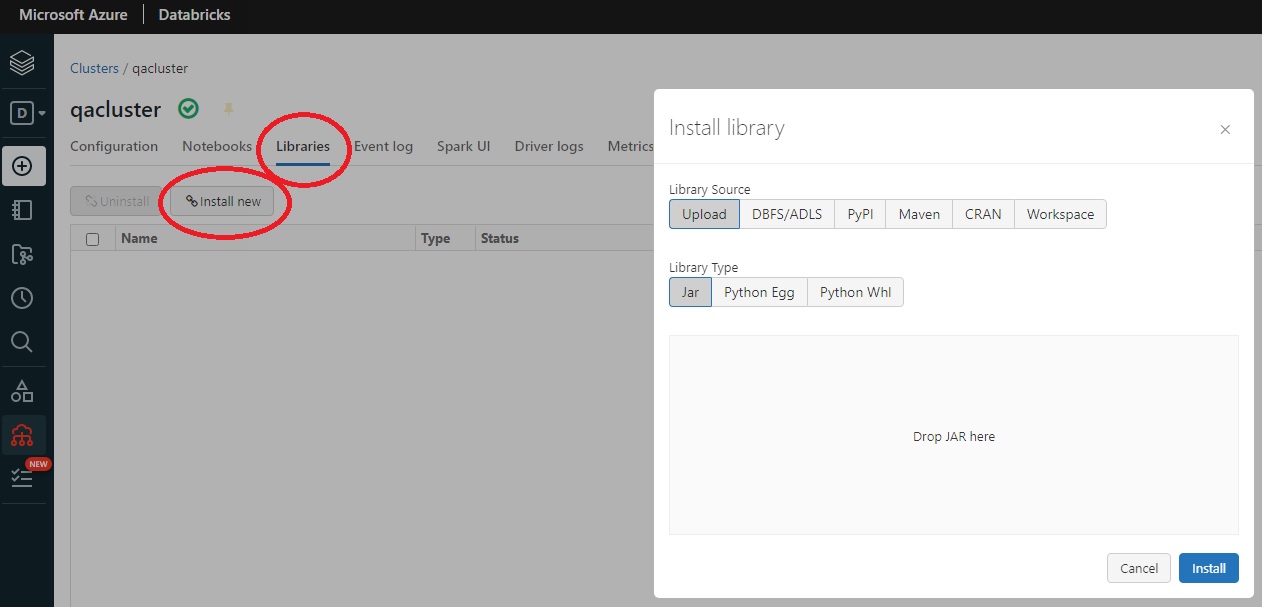
- Select Libraries/Install New/Upload/Jar
- Drop the JAR file SqdrSparkApply.jar (from C:\Program Files\StarQuest\sqdrplus\Tools)
Click Install. - Or, if you are updating to a newer version of SqdrSparkApply.jar, delete the library from the cluster, restart the cluster, and then add the new jar file.
- Select Libraries/Install New/Maven
- Enter the following for Coordinates (or something similar to this example, as there may be a newer version appropriate for your Spark environment). To view the available packages, click Search packages, select Maven Central from the dropdown, and enter azure-eventhubs-spark in the text field.
com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.22
Databricks Notebook Setup
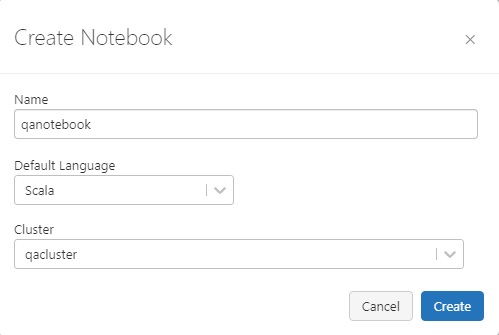
Select the + sign in the left column and select Create Notebook
- Give it a name
- Default Language: Scala
- Cluster - select the appropriate cluster
- Paste in the sample Scala code from C:\Program Files\StarQuest\sqdrplus\tools\readme.txt
- Edit the sample code, using values from the Event hub connection string
For example,. if the Event hub connection string looks like this:
Endpoint=sb://qanamespace.servicebus.windows.net/;SharedAccessKeyName=qahub1_policy;
SharedAccessKey=gGKrXXXXu4wT11VIRebtm6cXXXX1uogZbXxlUSvwu8U=;
EntityPath=qahub1
set the values as shown:
namespaceName = "qanamespace"
eventHubName = "qahub1"
dbLocation = "/user/hive/warehouse/"
deltaLocation = "/FileStore/tables/"
val sasKeyName = "qahub1_policy"
val sasKey = "gGKrXXXXu4wT11VIRebtm6cXXXX1uogZbXxlUSvwu8U="
Run the Scala code:
In the upper right corner of the work area, next to the control containing the words Scala, click the Run symbol and select Run Cell
or enter Shift+Enter

Observe the bottom of the screen for job progress.
If there are any errors, fix them.
Otherwise, the job is running and waiting for input from the Event Hub.
Note that the job runs continuously, keeping the compute cluster active (i.e. the 15 minute inactivity timer will not be effective), incurring non-trivial charges. If there is no work to perform, stop the job by selecting Stop Execution at the top of the screen.
In a typical scenario, you may want to set up a job to run the notebook on a scheduled timer.
The messages will be retained in the event hub; verify that the event hub has been configured with adequate storage/retention.
To view the resulting data:
- Create a new notebook of type SQL and enter a SQL statement.
or
- Select Data from the left column and navigate to Database and Table. You can view the schema, sample data, creation and modification dates.
To return to the notebook later, select Compute from the left column, open the cluster (which should be running), and select Notebooks.
Creating an SQDR destination using the Simba ODBC driver
If you are interesting replicating only incremental change data to Databricks, using the Simba ODBC driver is optional; instead you can use any destination e.g. the SQDRC control database as a place-holder destination.
However, installing and configuring the Simba ODBC driver to communicate with Databricks can also handle creation of the destination tables. In addition, you can use the driver to replicate the baseline, though in most cases using Kafka for the baseline is recommended.
- Download the Simba Spark ODBC driver (aka Databricks ODBC driver) from Databricks.
- Install the driver
Obtain connection information from the Databricks workspace:
- Generate a token (to be used in place of a password):
- Select your userID in the upper right corner.
- Select User Settings.
- Go to the Access Tokens tab.
- Select the Generate New Token button. Be sure to save the token, as there is no way to recover it other than generating a new token.
- Obtain the connection string:
- Select Compute icon in the sidebar.
- Select your cluster.
- Select Advanced Options.
- Select the JDBC/ODBC tab.
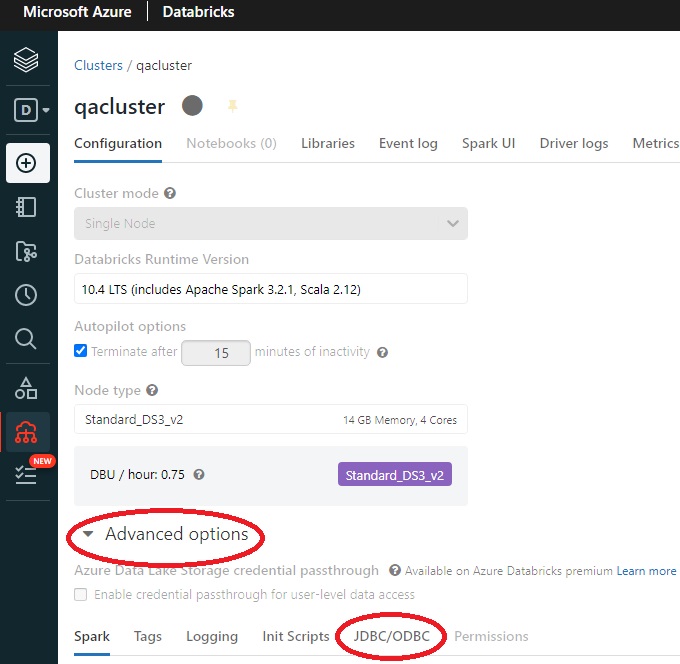
Copy the JDBC connection string and modify it as follows:
Starting with the JDBC connection string obtained from Databricks:
Example:
jdbc:spark://adb-nnnnn.0.azuredatabricks.net:443/default; transportMode=http;
ssl=1;httpPath=sql/protocolv1/o/555548385517300/0555-075538-pmvjaabc;AuthMech=3;
UID=token;PWD=<personal-access-token>
- Remove the UID & PWD parameters
- Convert the JDBC URL to host, port and database parameters, changing
jdbc:spark://<hostname>:443/default
to
host=<hostname>;Port=443;Database=default
- Change
transportMode=http
to
ThriftTransport=2
resulting in an ODBC connection string that can be used in Data Replicator Manager:
host=adb-nnnnn.azuredatabricks.net; Port=443;Database=default;ThriftTransport=2; ssl=1;httpPath=555548385517300/0555-075538-pmvjaabc;AuthMech=3
Create a destination in Data Replicator Manager, paste in the connection string as above, specify the name token as the user, and provide the token generated above as the password.
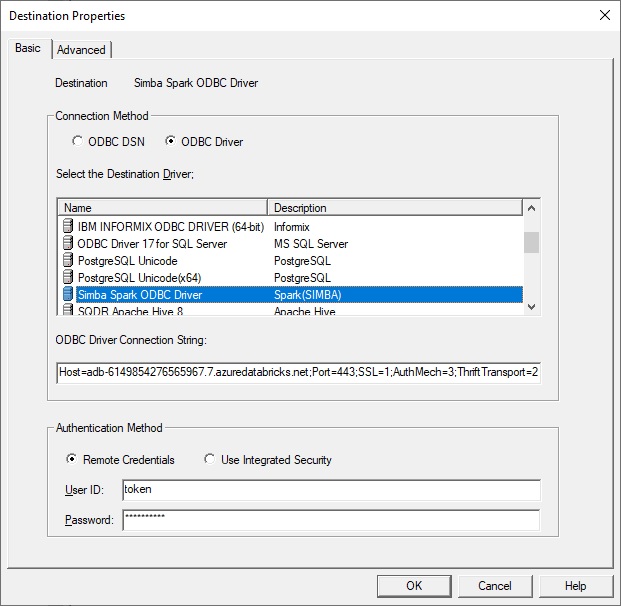
If you prefer to use an ODBC data source, extract the parameters from the connection string or from the JDBC/ODBC display and specify:
- Host adb-895148384217555.0.azuredatabricks.net
- Port 443
- Mechanism: select User Name and Password from the dropdown
- ThriftTransport: select HTTP from the dropdown
- Next choose the SSL button and select the Enable SSL checkbox
- Select HTTP Options and enter HTTPPath: sql/protocolv1/o/895558384217300/0520-210341-dvybvgij
- Database default or a schema that you have created (or it can be left blank)
On the Advanced panel of the Destination, change the default schema on the Advanced panel from token to the name of an existing Databricks schema.
Select the checkbox Stream(Using Apply extensions), and optionally specify a directive for to be appended to the Create Table e.g.
USING DELTA LOCATION '/FileStore/tables/^f'
Specify ^~d instead of ^f if you do not want quotes around the table name. Select the Help button to see the options for this parameter.

Configuring the SQDR Incremental Group
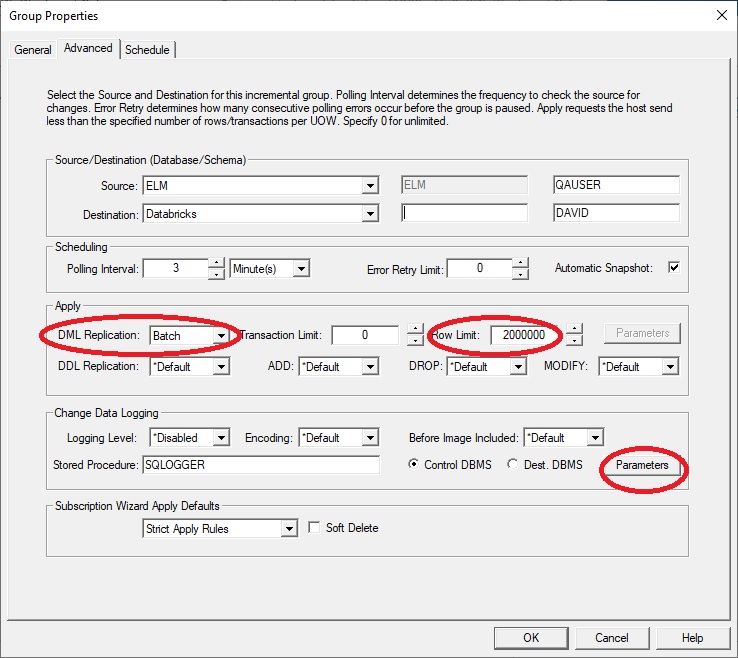
You will use the connection string from the Event Hub as part of the connection information (the Password parameter) entered in Parameters of the Advanced dialog of the incremental group.
Also verify that the DML Replication type is Batch.
For example, if the Event Hub connection string is:
Endpoint=sb://qanamespace.servicebus.windows.net/;SharedAccessKeyName=qahub1_policy;
SharedAccessKey=gGKrXXXXu4wT11VIRebtm6cXXXX1uogZbXxlUSvwu8U=;EntityPath=qahub1
You would paste the following into the Parameters field, substituting appropriate values for the items in italics:
className=com.starquest.sqdr.apply.kafka.KafkaSparkProcessor
topic=qahub1
batch.size=524288
linger.ms=200
bootstrap.servers=qanamespace.servicebus.windows.net:9093
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="Endpoint=sb://qanamespace.servicebus.windows.net/;
SharedAccessKeyName=qahub1_policy;
SharedAccessKey=gGKrXXXXu4wT11VIRebtm6cXXXX1uogZbXxlUSvwu8U=;EntityPath=qahub1";
Creating a Subscription
If the goal is incremental change data only, then configure the destination panel of the subscription specifying Baseline Replication Options to Append replicated rows to existing data and Null synchronization - DDL only as shown here.
Baselines can be performed using Kafka messages generated from SQDR Plus (Tier 2) by setting the following conditions:
• Use Native-Loader Function (Bulk Loader) is selected on the destination panel of then incremental subscription
• Stream Data (Kafka) checkbox is selected on the destination (advanced panel)
If Insert using ODBC is specified instead, then baselines will be performed using the ODBC driver.
When creating subscriptions, we recommend using lower case for destination table names.
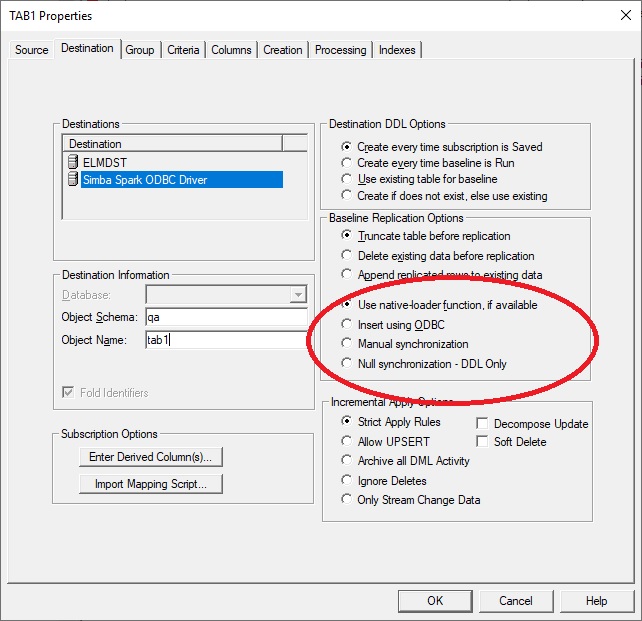
After creating the subscriptions, if Automatic Snapshot (on the advanced panel of the group) is enabled (default), the group is run automatically after creating the subscriptions.. Otherwise, enable capture & apply.by running the subscriptions or the group.
Troubleshooting
To verify network connectivity to Azure event hubs, use the powershell command
Test-NetConnection -ComputerName <host> -Port <port>
e.g.
Test-NetConnection -ComputerName mynamespace.servicebus.windows.net -Port 9093
The following error may appear in db2diag.log or an error message when an invalid hostname or IP address is supplied in Parameters.
No resolvable bootstrap urls given in bootstrap.servers
Issue:
The following error was displayed in Data Replicator Manager when creating the incremental group
Stored procedure SQDR.PUSHCHANGES returned error 11. Unexpected native error: Unable to load class: com.starquest.sqdr.apply.kafka.KafkaSparkProcessor. See Agent Diagnostics in Control Center for more detail.
Examing the Agent Diagnostics displayed additional information:
CaptureAgentLog: getProcessorUnable to load class: com.starquest.sqdr.apply.kafka.KafkaSparkProcessor
...
Caused by: org.apache.kafka.common.KafkaException: Failed to construct kafka producer
...
Caused by: java.lang.IllegalArgumentException: JAAS config entry not terminated by semi-colon
at org.apache.kafka.common.security.JaasConfig.parseAppConfigurationEntry(JaasConfig.java:121)
Solution: Be sure there are no extra linefeeds in the connection information in the Parameters. The value for sasl.jaas.config should be one long line.
Issue:
The following error was observed:
Stored procedure SQDR6.PUSHCHANGES returned error 10. Logic error: Missing configuration properties.
Solution: This error was observed in a split tier environment. We recommend using a combined tier environment so that the SQDR Plus agent has access to the SQDRC control database used by SQDR in order to obtain the configuration parameters.
Issue:
When creating a subscription with the Simba Spark ODBC driver, you receive a warning that the destination table does not exist, even when it does.
Solution: Table names in Databricks/Spark are typically lower case. Instruct SQDR to use lower case by unchecking Fold Identifiers on the Destination panel of the subscription and confirming that the destination table name is lower case.
Hints & FAQ
Question: The statistics for the subscription show that rows have been sent, but I do not see them in Databricks.
Answer: The statistics represent the number of rows that have been delivered to Azure Event Hub; SQDR does not have visibility into Databricks activity. Make sure that the Scala code in the Notebook is active. If it is not running, the data is retained by the Azure Event Hub if it has been configured for retention. Event Hubs Standard tier supports a maximum retention period of seven days.
DISCLAIMER
The information in technical documents comes without any warranty or applicability for a specific purpose. The author(s) or distributor(s) will not accept responsibility for any damage incurred directly or indirectly through use of the information contained in these documents. The instructions may need to be modified to be appropriate for the hardware and software that has been installed and configured within a particular organization. The information in technical documents should be considered only as an example and may include information from various sources, including IBM, Microsoft, and other organizations.